Golden Datasets, Eval Data, and Fine-Tuning Sets: Built by DataFramer
Raw LLMs can't generate multi-file records, edge cases, or labeled data at the fidelity AI teams need.

Puneet Anand
Thu Mar 26
Raw LLMs can generate samples, but they struggle to produce production-grade datasets with the structure, coverage, and reliability AI teams actually need. DataFramer fills that gap by generating complex, realistic data for training, evaluation, regression testing, red teaming, and fine-tuning. You control the distributions, scenarios, edge cases, and labels you need, rather than relying on whatever a model happens to produce. It works on the formats most tools break on (multi-file records, nested documents, long-form content, financial documents, and multi-turn conversations), checks and corrects its own output, and labels the data for you, with optional human review for high-stakes domains.
At a glance
| Differentiator | Why it matters |
|---|---|
| Multi-format, multi-structure generation | Tabular, short text, long-form documents, and multi-file samples. Modern AI systems depend on mixed data shapes. |
| Real Controllability | Start from what your data actually looks like; extract distributions and shape into editable rules you can reproduce or vary precisely |
| Few seed samples are all you need | Start from a handful of examples, or from requirements alone. Useful when real data access is limited or restricted. |
| Built-in evaluations | Evaluation runs as a first-class artifact with reporting and chat, so you can measure fitness for your downstream task |
| Dataset annotation, golden datasets, and human review | Ground truth labels and golden datasets attached at generation, with in-app expert review for high-stakes domains. Closes the loop before data ships to training or evaluation. |
| Flexible deployment and integration | Deploy on your own network or let DataFramer host it; UI for exploration, REST API for scale. Your data never leaves your environment. |
| Domain-specific fidelity | Purpose-built validation including math, SQL, conformance, PDF/formats, and much more. |
| Overcoming the limitations of raw LLMs | Structured workflow that prevents drift on layout, formatting, arithmetic, hallucination, and output collapse. Addresses what raw LLMs get wrong at scale. |
| Fairness, edge cases, and red teaming | Increase representation, simulate rare events, and generate adversarial suites for prompt injection and jailbreaks, all in the same workflow. |
1. Multi-scenario generation across real data formats
Many organizations need synthetic datasets that look like production edge-cases, not simplified examples. That can include long documents, multi-turn conversations, agent trajectories, tool call sequences, mixed structured / unstructured data, multi-file records, and more.
DataFramer treats “a sample” as the unit you care about, whether that is a row, a file, or a folder. This helps when your use case involves bundled artifacts rather than single records.
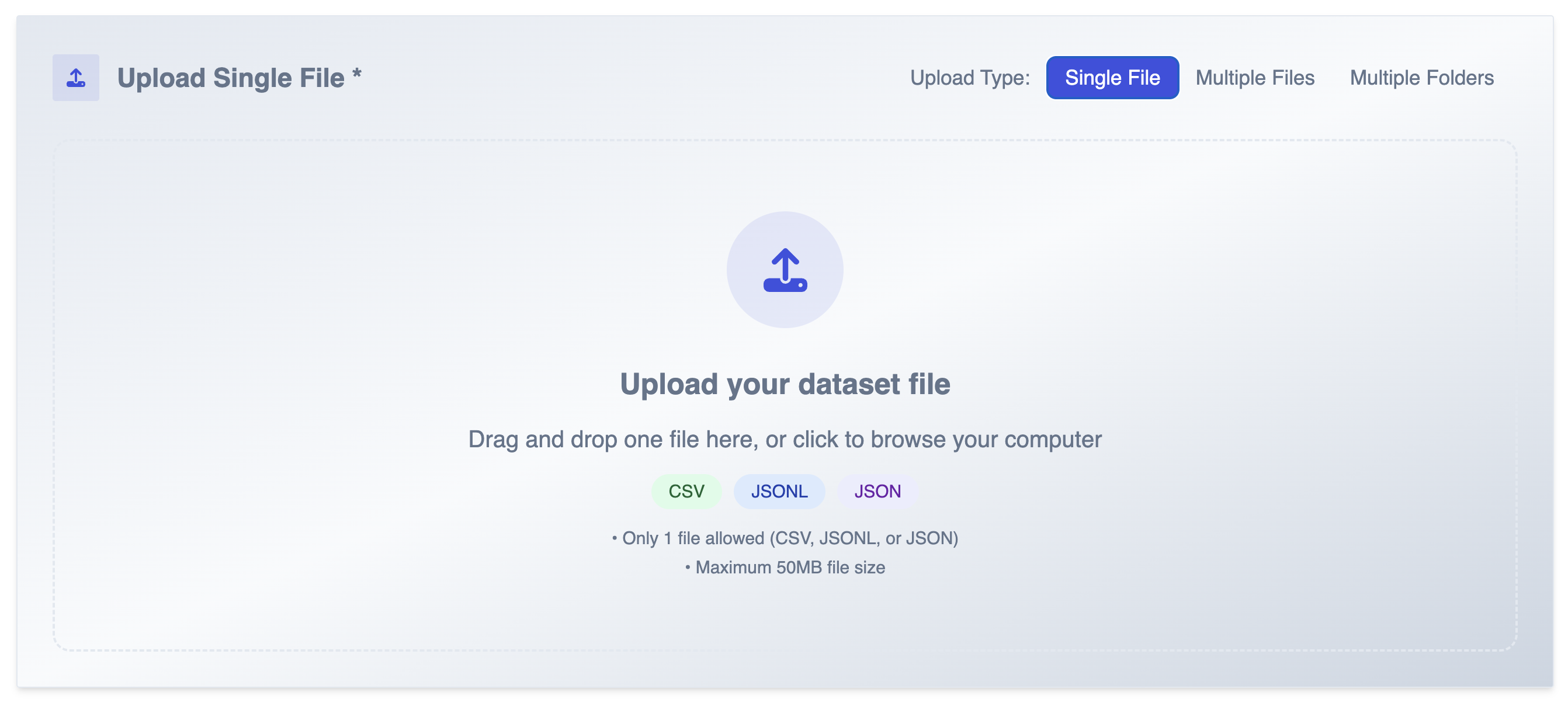
2. Real Controllability
“Control” is only valuable if it helps you create the dataset variants you actually need: higher edge-case density, specific distributions, constrained fields, and consistent outputs across versions.
DataFramer emphasizes control across requirements, distributions, and workflow configuration, including choosing different models for different roles in the pipeline.
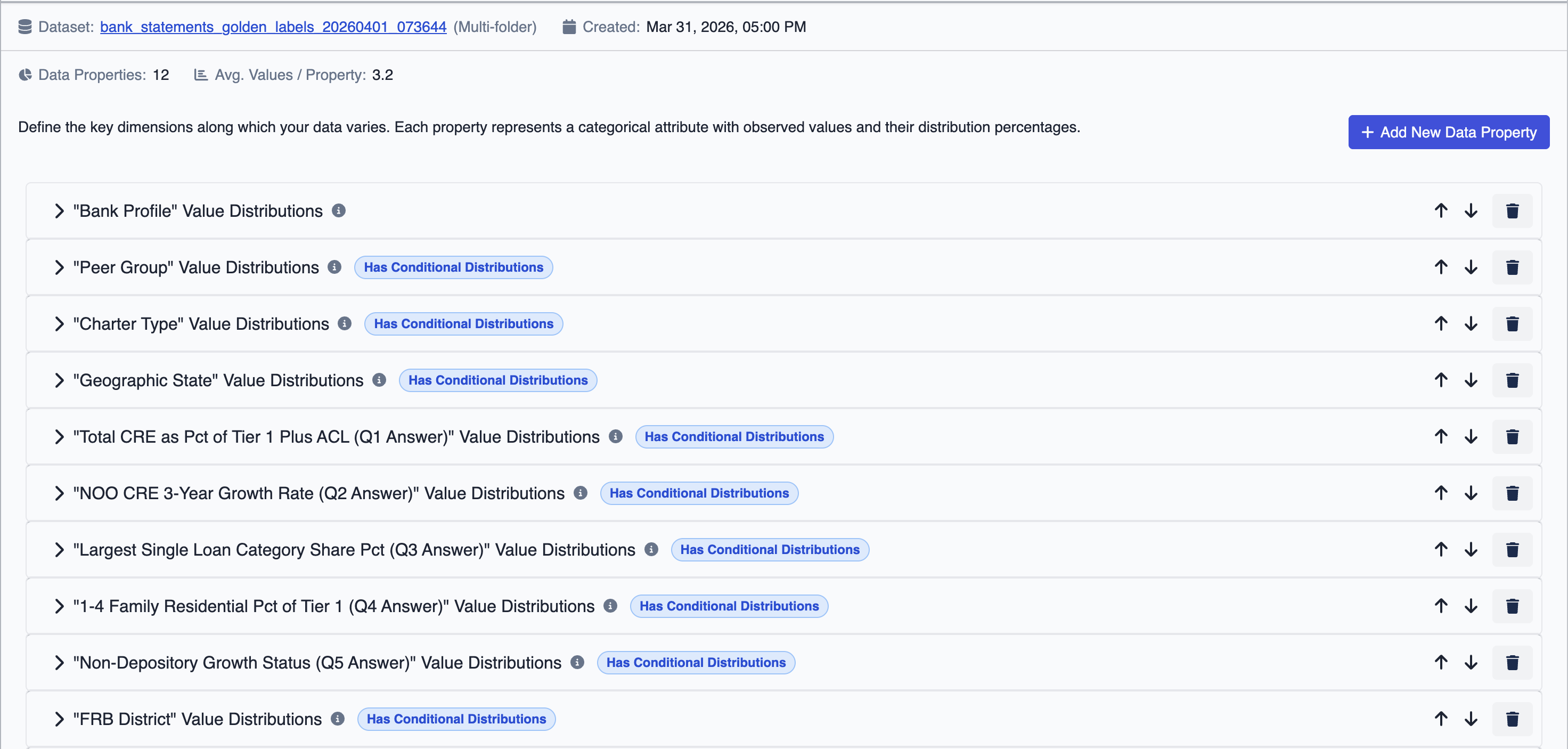
Before you configure anything, DataFramer analyzes your uploaded dataset to extract statistical distributions of values and properties, plus the structural shape of your data. This analysis becomes the starting point for your generation rules: you can inspect it, adjust distributions, and modify the shape before generating, rather than specifying everything from scratch.
This includes model de-biasing: DataFramer surfaces and corrects innate model habits, such as defaulting to Markdown structure when plain text is required, that accumulate silently across large runs.
3. Few seed samples are all you need
A common bottleneck is that teams cannot access many real samples due to privacy restrictions, contracts, or internal governance. DataFramer supports seed-light workflows and can also work from requirements when seeds are unavailable.
When real data exists but contains PII or PHI, DataFramer can de-identify and mask it before using it as seed data, preserving statistical distributions and structural shape without exposing sensitive information. This makes it practical to generate privacy-safe synthetic data from production data that could not otherwise leave a controlled environment.
4. Built-in evaluations
Synthetic data should not be evaluated by “it looks realistic.” What matters is fitness for a specific downstream use: does it improve evaluations or expose weaknesses during testing? Does it match the expected distributions? Does it allow you to chat with your generated data?
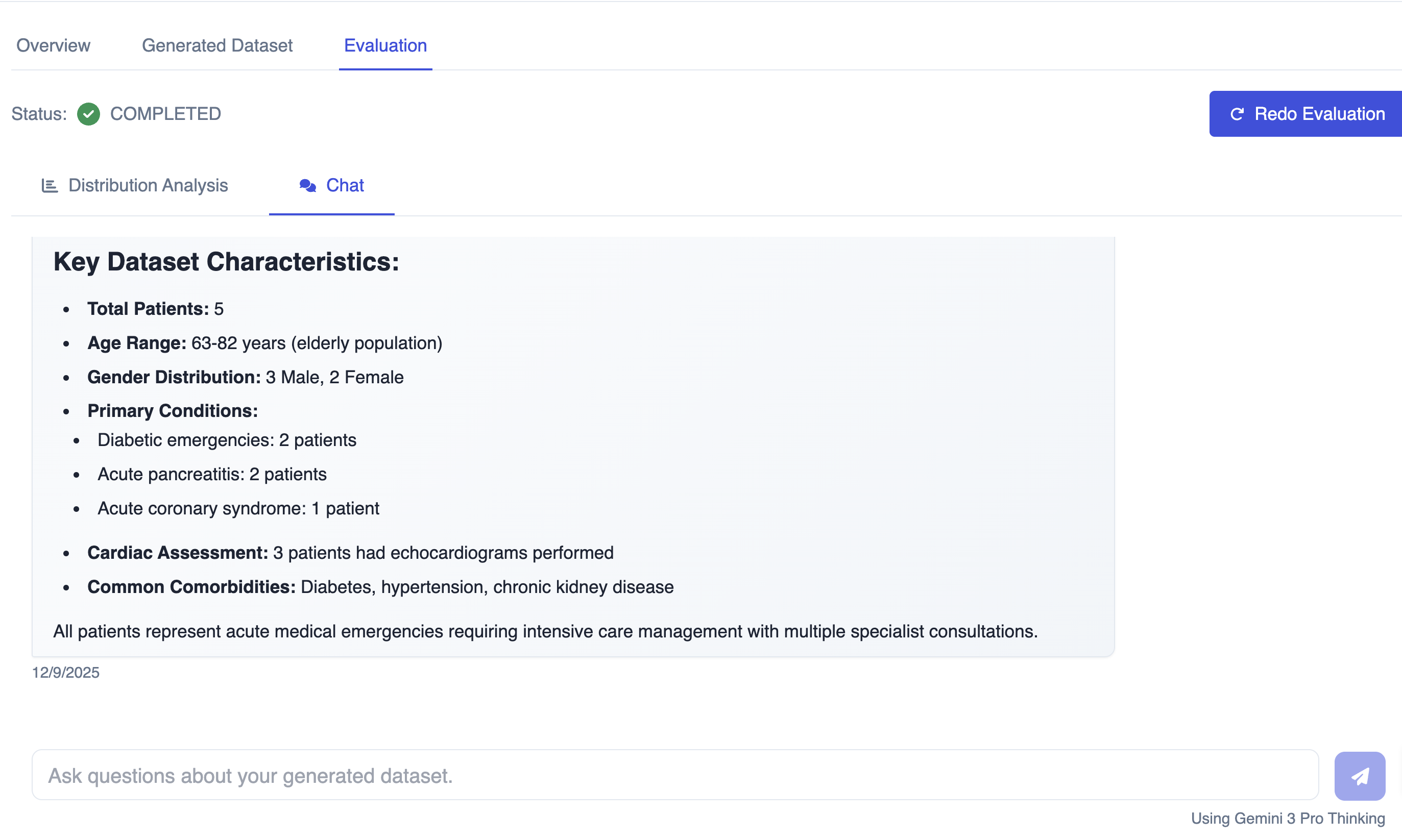 DataFramer includes built-in evaluation and reporting workflows so teams can measure quality, compare dataset versions, and diagnose failures quickly. The built-in evaluations compare expected vs. observed distributions across properties, assign LLM-as-a-judge labels to each generated sample, and include a chat interface for querying the dataset directly, giving teams a quality signal without a separate review step.
DataFramer includes built-in evaluation and reporting workflows so teams can measure quality, compare dataset versions, and diagnose failures quickly. The built-in evaluations compare expected vs. observed distributions across properties, assign LLM-as-a-judge labels to each generated sample, and include a chat interface for querying the dataset directly, giving teams a quality signal without a separate review step.
5. Dataset annotation, golden datasets, and human review
DataFramer generates datasets with ground truth labels attached, producing golden datasets ready for tasks like evaluations, fine-tuning, instruction tuning, post-training without a separate labeling step.
For high-stakes use cases, DataFramer includes an in-app human review interface where domain experts can inspect samples and make corrections before the dataset ships. This is particularly useful in domains like medical, legal, and financial data, where human-in-the-loop evaluation and subject matter expert annotations are a requirement rather than a nice-to-have.
For teams that need it, DataFramer can also provide vetted domain reviewers directly, so you are not on your own to source qualified annotators. Talk to us about your specific needs.
6. Flexible deployment and integration
DataFramer can be deployed on your own trusted infrastructure (or hosted by us). This matters most in regulated industries and enterprise settings where data residency, compliance, and vendor access policies make cloud-only tools a non-starter.
It also works in two modes: fast interactive exploration via UI, and reliable scaled generation via a REST API designed for programmatic workflows. A non-technical domain expert can author a specification with desired distributions and requirements, and then pass it to a developer lead to use repeatably through an API.
7. Domain-specific fidelity including Math, SQL, and PDF
Some data types have hard correctness requirements that “looks realistic” cannot satisfy. DataFramer includes purpose-built validation for three of these:
- Mathematical correctness across spreadsheets and tables, ensuring calculations, totals, and cross-cell dependencies are consistent to 99.99% accuracy
- Code and query validation, with text-to-SQL as the primary example: a purpose-built SQL verifier that checks generated queries for semantic correctness, not just syntax
- PDF generation, structured generation of complex PDFs that preserves layout fidelity beyond what standard LLM outputs produce
These are particularly relevant for Financial Services and Insurtech use cases where arithmetic or document errors are not tolerable.
8. Overcoming the limitations of raw LLMs
Raw LLMs hit predictable walls when used for data generation. They cannot sustain long documents: outputs drift, compress into summaries, and lose diversity as length grows. They hallucinate facts and fabricate values. They are unreliable at arithmetic. At scale, they converge: ask for 500 samples and you get clusters of near-duplicates, not a real distribution.
DataFramer’s workflow addresses each of these. Long documents are generated through outlines, drafting, and revision cycles that hold structure well beyond 50K tokens. Domain-specific validators check and correct math, SQL, and PDF layout. Distribution controls keep outputs spread across the scenario space you defined, not collapsed around the most common LLM defaults.
We tested this directly. In our Claude Sonnet 4.5 study, the DataFramer workflow outperformed baseline prompting using the same underlying model on diversity, style fidelity, length, and overall quality. The generation workflow matters as much as the model when you need consistent long-form results.
If long-form data is part of your roadmap, a useful test: ask any platform to generate long documents from the same seeds, measure diversity and fidelity, and check how well the workflow corrects failures without manual intervention.
9. Fairness, edge cases, and red teaming
Two problems show up repeatedly in production systems: skewed coverage and missing tails. Teams may need to increase representation, simulate rare events, and stress systems with adversarial conditions. DataFramer supports this as part of the same generation workflow, including adversarial suites for prompt injection and jailbreaks, stress testing datasets targeting known failure modes, and regression datasets for catching regressions before they reach production, making red teaming systematic and repeatable rather than ad hoc.
DataFramer datasets powering HDM-2 and HDM-Bench
DataFramer is built by the team behind AIMon Labs. We used it to build the datasets for HDM-2, a 3B parameter hallucination detection model that outperformed zero-shot GPT-4o on TruthfulQA and HDM-Bench, and reached state-of-the-art on RagTruth. Careful dataset design and repeatable evaluation changed the outcome.
A customer’s story: An InsurTech AI company scaling Life, Health, and P&C underwriting AI without sharing sensitive customer data
Insurance underwriting data is some of the hardest data to work with. It is sensitive, customer-owned, and often includes PII and PHI. That creates a practical constraint: you cannot easily reuse production data across engineering, product, design, and go-to-market workflows, even when everyone is working on the same AI system.
Even more so, this situation results in stalled POCs with customers who in turn can’t hand over their customer data to vendors.
One InsurTech AI company we worked with ran into exactly this problem as they expanded across multiple lines of business and enterprise customers.
They needed datasets that were realistic enough to drive rapid feature testing, stable enough for regression testing, and safe enough to use broadly inside the company and with external partners during pilots.
DataFramer generated synthetic EHR datasets and insurance submissions (patient histories, encounters, labs, and clinical journeys) reviewed by MDs and EMTs for medical fidelity.
Resources
- DataFramer Documentation: https://docs.dataframer.ai/
- Complete Workflow Guide: https://docs.dataframer.ai/workflow
- DataFramer vs Claude Sonnet 4.5 Long-text generation study: https://www.dataframer.ai/posts/long-text-generation-dataframer-vs-baseline/
- HDM-2 on Hugging Face: https://huggingface.co/dataframer/hallucination-detection-model
- HDM-Bench on Hugging Face: https://huggingface.co/datasets/dataframer/HDM-Bench
Generate Synthetic Data with the DataFramer MCP Server
Generate diverse synthetic data directly from your AI coding assistant using the DataFramer MCP server.
 Alex Lyzhov
Alex Lyzhov A Practical Guide to Evals, Testing, and Fine-Tuning with Synthetic Data
Why AI teams keep running into the same data problems, and what it actually takes to get past them.
Puneet Anand Get started
Ready to build better AI with better data?
The real bottleneck in AI isn't intelligence. It's the data you can't generate, can't share, or can't trust.