A Practical Guide to Evals, Testing, and Fine-Tuning with Synthetic Data
Why AI teams keep running into the same data problems, and what it actually takes to get past them.

Puneet Anand
Fri Aug 22
Table of Contents
- Table of Contents
- Why AI Teams Keep Running Into the Same Wall
- What Synthetic Data Is (and What It Isn’t)
- The Three Real Problems It Solves
- Types of Synthetic Data AI Teams Actually Use
- How It Gets Generated, and Why the Method Changes Everything
- Anonymization vs. Synthetic Generation: Not the Same Thing
- What Good Synthetic Data Has to Preserve
- Where It Fits in the AI Development Lifecycle
- Four Stories from the Field
- What to Look For When Evaluating Tools
- Where DataFramer Fits
- References
Why AI Teams Keep Running Into the Same Wall
A pattern we see often: a team builds a workflow, tests it, results look reasonable, and then something breaks in production that nobody saw coming. Not because the model was bad. Because the data the model was tested on didn’t reflect what it actually faced once it was live.
This isn’t unusual. McKinsey’s 2024 AI reporting found that managing data remains one of the main barriers to scaling AI, including issues with data quality, governance, and having sufficient training data.[1] The problem isn’t that teams don’t know how to build models. It’s that the data available to train and test those models is incomplete in ways that only become obvious after deployment.
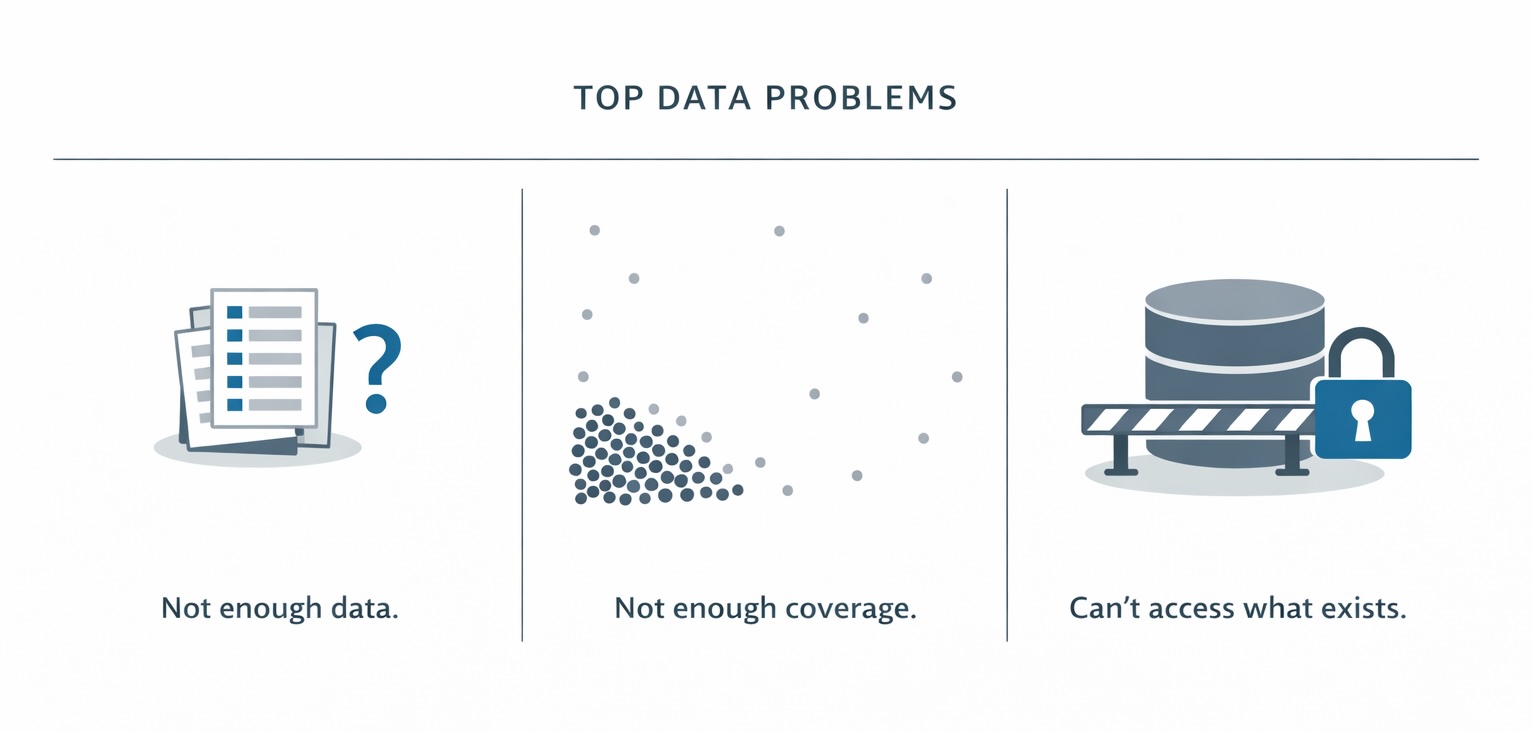
There are usually a few versions of this:
The dataset is too small. You have examples, but not enough to cover the range of inputs the model will encounter. Fine-tuning on 500 examples when production handles 10,000 different kinds of requests is a recipe for gaps.
The dataset is too narrow. You have plenty of data, but it’s concentrated around the easy cases. Rare, awkward, or edge-case inputs that cause real problems are underrepresented, sometimes by a factor of 100 to 1.
The dataset is off-limits. The data that would actually make the model better is sitting somewhere it can’t be accessed for development or testing.
Synthetic data addresses all three. Not as a magic fix, but as a practical way to extend what you already have.
What Synthetic Data Is (and What It Isn’t)
Synthetic data is data that was generated, not collected. Instead of recording real events or capturing real user behavior, you use a model or algorithm to produce new records that follow the same patterns as real data.
The key word is patterns. A synthetic record is not a copy of a real one. There is no real person behind it or real transaction underneath it. But it should behave like there is, statistically. The distribution of values, the correlations between fields, the kind of variation you would expect in the real world: those should be preserved.
This is different from placeholder data written by hand. Made-up records don’t have statistical fidelity, and models can tell. It’s also different from anonymized data, which we’ll come back to later because that distinction matters more than most teams realize.
Internally at DataFramer, we use a term called “data shape” to describe keeping the patterns faithfully.
The place synthetic data is most useful is not as a replacement for real data. It’s as an extension of it. Most teams we’ve worked with at DataFramer had some real data already. The question was whether they had enough of it, enough variety, and enough coverage to actually trust what their evals were telling them.

The Three Real Problems It Solves
1. Your seed data isn’t enough
You have real examples, but not enough of them. Evaluating AI agents, training a classifier, fine-tuning a language model, building a retrieval corpus: all of these are sensitive to how much and how varied the signal in your data is.
Research on scaling laws in neural language models established that performance follows predictable patterns as a function of dataset size, model size, and compute.[2] The practical implication for teams building eval and fine-tuning datasets is that bigger is not the only thing that matters. Coverage matters too. A dataset of 10,000 examples clustered around the same kinds of inputs is often less useful than 2,000 examples spread across a diverse range of cases.
Good synthetic generation lets you take the seed data you have and extend it in controlled ways. Not by copying records, but by generating new ones that introduce variation within the range your seed data defines. You keep the structure. You expand the coverage.
2. Your real data is off-limits
Consider Healthcare. Patient records are protected. You can’t hand a dataset of real clinical notes to a model development team without going through significant data access processes, most of which take months.
The same dynamic shows up in financial services, legal, and any domain where records are tied to identifiable individuals.
Teams building AI tools in these domains often can’t touch the data that would make the tools actually work. They prototype on public datasets, then hit a wall when they try to validate on something realistic.
Diverse synthetic data changes that. If you can learn the statistical structure of the real data, you can generate new records that preserve the population-level patterns without containing any real individuals.
3. Your data doesn’t cover what your model will face
This one surprises teams most often, because it’s not a volume problem. You can have millions of records and still not have the right ones.
Let’s use Fraud detection as an example. Real transaction datasets are heavily imbalanced: the vast majority of transactions are legitimate, and the fraudulent ones are rare. A model trained on that distribution learns, correctly in a narrow sense, that most things are fine. But it doesn’t learn enough about what fraud looks like, because it sees so few examples of it.[3]
The same pattern appears in evaluation. If your eval set only contains average-difficulty examples, a model can pass it without actually being good at the hard cases. Synthetic generation lets you target the coverage gaps directly: rare scenarios, edge cases, inputs that real data underrepresents because they don’t happen often enough to accumulate naturally.
Types of Synthetic Data AI Teams Actually Use
Most writing on synthetic data lists image, video, audio, text, and tabular as the main types. That breakdown is fine for a broad overview, but it doesn’t quite match how AI teams in practice think about what they need.
Tabular and structured datasets
Rows and columns: transaction records, log data, structured survey responses, entity databases. This is the most mature area of synthetic data generation, with well-understood methods and strong tooling. Tabular synthesis is where you’re most likely to care about preserving correlations between fields, not just the marginal distribution of each field individually.
Text and document datasets
Unstructured text, whether that’s customer messages, support tickets, medical notes, contracts, or other document types. Generating useful synthetic text requires preserving not just vocabulary but also writing style, structure, domain-specific terminology, and the realistic messiness of real documents. Synthetic clinical notes that look too polished aren’t useful because they don’t reflect what real clinical notes actually look like.
Time-series and event sequences
Server logs, sensor readings, clickstream data, financial time series. These require generating realistic sequential patterns rather than independent samples. Temporal structure, autocorrelation, and seasonality all need to be preserved for the data to be usable.
Eval and test datasets
This category doesn’t get named often enough, but it’s where we at DataFramer see a lot of demand. An eval dataset has specific requirements. You need evaluation sets with question-answer pairs or input-output examples, context sets that represent structured or document datasets, and labels/annotations that reflect a specific distribution of difficulty, topic, and format. Generating these from scratch is hard. Extending a small set of hand-labeled examples into a broader, well-distributed eval set is one of the most common problems teams bring to us.
Scenario and edge-case datasets
Data designed specifically to represent conditions that rarely appear in real datasets: unusual input formats, out-of-distribution requests, borderline cases that stress-test decision boundaries. These are generated not to match what the training distribution looks like, but to explore what’s outside it.
How It Gets Generated, and Why the Method Changes Everything
Not all synthetic data is created the same way. The generation method determines how much the output can actually be trusted, what it will be good for, and where it is likely to break. That is probably the most important thing to understand before choosing a tool or an approach.
Augmentation
Start with existing records and introduce controlled variation. Change the wording but not the meaning. Shift values within a plausible range. Apply transformations that preserve the original label or intent. Augmentation works best when you already have real examples and want to expand the dataset without moving far from the original distribution. It is conservative, which is both its strength and its limit.
Pattern-preserving generation
Train a model on your real data so it learns the statistical relationships between fields or features, then generate new records by sampling from that learned representation. The output does not match any real record, but it should reflect population-level patterns in the original dataset. This is a common approach for tabular data and includes methods such as copulas, Bayesian networks, VAEs, GAN-based models, and newer generative approaches.
Simulation
Define the process that produces the data, then generate samples from that process using rules, constraints, probability distributions, or state-based models. Simulation is useful when you want explicit control over the generation process rather than relying on patterns learned from historical data. Insurance teams use simulation to generate claims data for scenarios that have not happened yet. Autonomous vehicle teams use it to create training data for rare driving situations that are not well represented in real logs.
Generation from scratch
Generate data without training on your actual dataset, using a general-purpose model prompted with a description, schema, or examples. This can produce fluent, readable output quickly, but without grounding in your real data, the result may be plausible in a generic sense while still missing the distributions, dependencies, and edge cases of your domain.
The distinction that matters most: grounded vs. ungrounded
Ungrounded generation starts from a description of what you want. It is fast to begin with and easy to set up, but the output was not shaped by your actual data. Grounded generation starts from your real examples. The model learns what your data looks like: field distributions, co-occurrence patterns, stylistic conventions, and the edge cases that actually appear in your domain. The output extends from that foundation rather than inventing from nothing.
At DataFramer, though we provide a seedless generation feature (from scratch), we have built around the grounded approach for this reason. For teams that want synthetic data to reflect the structure and behavior of their real data, starting from real examples is usually more reliable than starting from a description alone.
Anonymization vs. Synthetic Generation: Not the Same Thing
This distinction comes up often because the two are used interchangeably and they aren’t the same operation.
Anonymization takes real records and removes or modifies identifying fields. Names get replaced. IDs get masked. Dates get shifted. The underlying records are still real. Every row in an anonymized dataset corresponds to a real person or real event. The data was real; it’s been edited.
The risk this creates is re-identification. Given enough context, anonymized records can sometimes be matched back to real individuals through cross-referencing with other data sources. This isn’t theoretical: Narayanan and Shmatikov published a demonstration of this against the Netflix Prize dataset in 2007, de-anonymizing records that had been considered safe.[4]
Synthetic generation doesn’t have this problem in the same way, because the shared output is newly generated rather than a row-level edit of an original record. In seed-based systems, the generator still learns from real data, but the goal is to produce records that are not tied one-to-one to a specific person or event.
The more practical difference for most teams, though, is data quality. Traditional anonymization degrades datasets in ways that matter for modeling. Masking fields reduces information content. Shifting dates changes temporal patterns. Replacing names and identifiers with placeholders breaks co-occurrence patterns that models were supposed to learn. Synthetic generation can preserve more of the statistical structure when it is designed to model those patterns directly instead of editing each original row.
One important caveat: synthetic generation doesn’t automatically guarantee privacy. Generative models can memorize real records, especially when trained on small datasets, and that memorization can show up in the output. Privacy guarantees require deliberate choices in how the generation process is designed, not just the choice to generate rather than anonymize.
| Aspect | Anonymization | Synthetic Generation |
|---|---|---|
| Starts from | Real records that are edited after collection | Learned patterns from seed data or a statistical model |
| Privacy approach | Masks, removes, or shifts identifying fields | Generates new records that are not tied to one original person or event |
| Re-identification risk | Reduced, but still possible with enough outside context | Lower when done correctly, but still depends on how the model is trained |
| Data quality impact | Can degrade utility by breaking dates, identifiers, and co-occurrence patterns | Better preserves statistical shape because there is no original row being edited |
| Best for | Sharing real datasets with reduced exposure when exact records still matter | Training, testing, and eval when real data is off-limits or too narrow |
What Good Synthetic Data Has to Preserve
This is what separates useful synthetic data from data that passes a quick visual check but fails when a model is actually trained on it.
Data shape
Each generated record should be internally coherent. Field values should be plausible, and the relationships between fields that exist in the real world should hold. If income and spending move together in real data, generated records should show the same pattern. Not because the seed data said so, but because records that break these relationships are not realistic and will not be useful.
Distribution as a design choice
How the generated data is spread across the dataset is something you decide based on what you need. Sometimes you want the generated data to follow the same distribution as your seed. Often you do not. A team working on fraud detection may want more fraudulent examples than the original data contains. A team building an eval set may want harder or rarer cases to appear more often. The distribution is a choice you make, not something you always carry over from the original data.
Schema and constraint integrity
Dates should be valid. Relationships between fields that are implied by domain logic should hold. Fields that are conditionally required should appear under the right conditions. Synthetic data that violates domain constraints won’t work in the same pipelines as real data, which defeats much of the practical value.
Realistic variation, not artificial uniformity
Real data is messy in specific ways. Some fields have long tails. Some records have missing values. Some text is more formal than others. Synthetic data that gets cleaned up too aggressively during generation ends up looking different from real data in exactly the ways that matter to models, even if it looks fine to a human reviewer.
Domain fidelity
For text, this means using the right terminology, writing conventions, and structure for the domain. Synthetic clinical notes that don’t look like actual clinical notes aren’t useful for training clinical NLP systems. Surface-level fluency and domain fidelity are different things. A model can produce text that reads clearly while completely missing the conventions of the target domain. Models trained on that data will feel the difference even when human reviewers don’t.
What good synthetic data has to preserve
The difference between data that looks right and data that trains well
01 2024-02-31 active EU/US
02 2024-01-15 pending —
01 2024-01-28 active EU
02 2024-01-15 closed US
The patient presented with acute
chest discomfort and shortness of
breath. Physical examination was
conducted. Treatment was initiated.
Pt c/o substernal CP x2h, SOB.
EKG: NSR, no ST changes. trop ×2
pending. Started ASA 325mg,
O₂ 2L NC. Admitting r/o ACS.
Where It Fits in the AI Development Lifecycle
Synthetic data isn’t a one-time thing you reach for when you’re stuck. It fits at multiple points in how AI systems get built and maintained.
Before you have enough real data
Early-stage model development is often blocked by the time it takes to collect and label enough data to start training. Synthetic augmentation lets teams get to a first working model faster by using a small seed of real labeled examples to generate a larger training set.
When building evaluation pipelines
Before you ship a model or workflow, you need to know how it performs. But building a comprehensive eval set by hand is slow, expensive, and usually produces something too narrow to catch real failures. Synthetic eval generation lets teams expand coverage, diversify difficulty, and systematically include the categories of input the model will face in production.
This is where we see the clearest return at DataFramer. An eval set with 50 hand-labeled examples can be expanded to 500 or 5,000, covering variations in topic, format, difficulty, and phrasing that the original 50 didn’t capture. The generated examples come pre-labeled, so teams are not trading the hand-labeling bottleneck for a different one, see how this works end to end in our financial document extraction tutorial. The model gets tested on something that actually resembles what production looks like.
Pre-production testing
Before deployment, teams need to test how the full system behaves under realistic input variety, not just the inputs used during development. Synthetic test sets provide the volume and variety to do this without waiting for production traffic to accumulate.
Fine-tuning with limited examples
Few-shot fine-tuning works well, but it’s sensitive to the quality and diversity of the examples used. A small fine-tuning set that covers only a narrow range of the target behavior will produce a model that does well on that range and poorly on everything else. Expanding the fine-tuning set synthetically can address this, as long as the expansion preserves the structure and character of the original examples.
Regression testing after changes
When a model gets updated, you want to know whether the update broke anything that was working. Regression test sets need to be stable, comprehensive, and representative. Synthetically generated regression suites can be version-controlled and updated systematically as the model evolves.
Where synthetic data fits in the AI development lifecycle
collection
model
setup
testing
tuning
& regression
Four Stories from the Field
The following examples are drawn from documented public work. They illustrate how organizations at different scales have used synthetic data to solve the same categories of problems described above.
Fraud detection at a major financial institution
Fraud is rare. In a typical transaction dataset, the ratio of legitimate to fraudulent transactions can be 1,000 to 1 or higher. A classifier trained on this distribution learns, in a narrow sense correctly, that almost everything is legitimate. It doesn’t learn enough about what fraud looks like.
J.P. Morgan has written publicly about using synthetic data to support fraud detection model training by increasing the share of fraudulent or anomalous transactions available to the model.[5] The goal wasn’t to replace real fraud data but to give models more examples of the minority class so they could better learn its structure.
The core problem here was coverage, not privacy. The data existed; there just wasn’t enough of the right kind.
Bias detection in multi-label models
Mastercard applies multi-label AI models across fraud prevention, anti-money laundering, and marketing. One challenge was studying whether those models were picking up unintended demographic biases. This is hard to investigate when the demographic data involved is sensitive and can’t easily be shared outside the organization.
Working with external researchers, Mastercard generated synthetic datasets that preserved the demographic structure of their real data without containing actual records.[6] These datasets were used to develop and test methods for detecting and correcting bias in multi-label settings. In the published case-study summary, the synthetic data was considered sufficiently private to share externally while still capturing meaningful relationships from the source data.
The interesting thing about this case is that the problem wasn’t primary model performance. It was the ability to study the model’s behavior safely. Synthetic data served as a tool for transparency, not just development.
Healthcare records for external research
Johnson & Johnson worked with external researchers who needed access to healthcare datasets. Traditional anonymization created a recurring problem: edited records were less useful because the anonymization process had degraded data quality in ways that mattered for the analysis. Researchers were getting technically compliant data that wasn’t analytically useful.
The alternative they explored was AI-generated synthetic healthcare records that preserved population-level patterns without containing real patient information.[7] In the documented case study, researchers and clients reported significantly improved analysis compared with the anonymized option that had not always met their needs.
This pushes back on the common assumption that synthetic data is necessarily a second-best option. In this case, the synthetic option appears to have worked better for the analysis the researchers needed.
Data collaboration across a regulated environment
A pharmaceutical company needed access to heart health data held by a Singapore-based research institute. The data existed but couldn’t be shared as-is because of regulatory constraints on the environment it was held in.
A*STAR, the research agency involved, built a pipeline to generate synthetic versions of the heart health data. The pharmaceutical company evaluated the synthetic data first to assess quality and relevance before committing to the formal data acquisition process.[8] Synthetic data served as a preview and a trust-building mechanism between organizations with different access constraints.
The Personal Data Protection Commission of Singapore documented this collaboration as an example of privacy-preserving data sharing in practice.
What to Look For When Evaluating Tools
The synthetic data tooling space has grown quickly and vendor claims tend to sound similar. A few criteria that actually separate tools that produce usable data from ones that produce data that looks fine but doesn’t help.
Does it start from your data?
Seed-based generation produces output that’s statistically grounded in your actual domain. Seedless generation from a text prompt is faster to begin but produces data that may look plausible while missing the specific distributions and patterns of your real data. For training, fine-tuning, or eval use cases, seed-based is almost always the right choice.
Can you see how well the output matches your real data?
Distribution comparison means you can verify, before generated data touches your model, that the output is statistically faithful to the original. Without this, you’re trusting the tool’s output with no way to catch systematic distortion. This matters especially for tabular data where correlations between fields are important, and for text where domain-specific conventions are easy to get wrong.
Does it handle complexity beyond rows and columns?
Many real AI workflows involve documents, not tables: PDFs, structured forms, multi-section reports, conversation logs, or mixed inputs. Tools designed for tabular synthesis often generalize poorly to these formats. Check whether multi-format and document-heavy workflows are a first-class use case for the tool or an afterthought.
Can humans stay in the loop?
For high-stakes eval sets or labeled training data, you’ll want the ability to review and approve samples before they go into a pipeline. Tools that generate and hand off without a review step are fine for some use cases, but most teams building production AI systems want human checkpoints at appropriate stages.
How is quality enforced?
Automatic revision loops, where the generation process checks its own output against defined criteria and re-generates when it falls short, make a meaningful difference in output consistency. One-shot generation produces whatever comes out first. Quality enforcement built into the loop produces more consistent output and reduces manual filtering.
Can it run in your environment?
If your data can’t leave your infrastructure, cloud-only tools won’t work. On-premise or private cloud deployment matters for many enterprise teams.
| Criterion | What good looks like | Red flag |
|---|---|---|
| Seed-based generation | Starts from real examples and extends the actual structure of your data | Generates from a prompt alone with no grounding in your real distribution |
| Distribution comparison | Lets you inspect how generated output matches the seed before using it | Asks you to trust the output without measurable comparison |
| Multi-format support | Handles tables, documents, conversations, and mixed-format workflows | Works for rows and columns only, then breaks on real document-heavy pipelines |
| Human review | Keeps experts in the loop for high-stakes eval and training sets | No review step before generated data enters a production workflow |
| Automatic quality enforcement | Uses revision, validation, and filtering loops to catch weak outputs | One-shot generation with heavy manual cleanup required afterward |
| Deployment flexibility | Runs in your cloud or on your own infrastructure when needed | Cloud-only setup that conflicts with enterprise data controls |
Where DataFramer Fits
We built DataFramer for the problems this article describes: teams who have real data but not enough of it, teams whose data is off-limits for development, and teams whose data doesn’t cover the range of conditions their models will actually face.
The core of how DataFramer works is seed-based. You bring your real examples. We learn from them, generate variations that preserve the structure and distribution of what you provided, and give you data you can trust for evals, testing, and fine-tuning.
A few specifics about how we approach this:
Distribution comparison is built in. Before you use generated data in a pipeline, you can see how it compares statistically to your seed. If the distributions don’t match what you need, you know before it affects your model.
DataFramer works with structured and unstructured data, including multi-file and mixed-format workflows. If your dataset is a folder of PDFs, a set of conversation logs, or a mix of structured and free-text fields, that’s a first-class use case, not an edge case we’re working around.
Human review is part of the workflow for teams that need it. For high-stakes eval or training sets, you stay in the loop.
DataFramer runs in the cloud or in your own environment. For teams in regulated industries or with strict data governance requirements, on-premise deployment means your data doesn’t leave your infrastructure.
DataFramer doesn’t replace your data. It works from it. If you have real examples to start from, we can help you take them further.
References
- McKinsey & Company. “A data leader’s technical guide to scaling gen AI.” July 8, 2024. https://www.mckinsey.com/capabilities/tech-and-ai/our-insights/a-data-leaders-technical-guide-to-scaling-gen-ai
- Kaplan, J., McCandlish, S., Henighan, T., et al. “Scaling Laws for Neural Language Models.” OpenAI Technical Report, 2020. arXiv:2001.08361.
- Chawla, N., Bowyer, K., Hall, L., and Kegelmeyer, W. “SMOTE: Synthetic Minority Over-sampling Technique.” Journal of Artificial Intelligence Research, vol. 16, 2002, pp. 321-357.
- Narayanan, A. and Shmatikov, V. “How To Break Anonymity of the Netflix Prize Dataset.” arXiv, 2007. arXiv:cs/0610105.
- J.P. Morgan. “Synthetic Data for Real Insights.” Technology Blog, September 2021. https://www.jpmorgan.com/technology/technology-blog/synthetic-data-for-real-insights
- Personal Data Protection Commission, Singapore. “Proposed Guide on Synthetic Data Generation.” 2024. Mastercard case study on bias detection in multi-label models. https://www.pdpc.gov.sg/-/media/files/pdpc/pdf-files/other-guides/proposed-guide-on-synthetic-data-generation.pdf
- Personal Data Protection Commission, Singapore. “Proposed Guide on Synthetic Data Generation.” 2024. Johnson & Johnson case study on synthetic health data for external research. https://www.pdpc.gov.sg/-/media/files/pdpc/pdf-files/other-guides/proposed-guide-on-synthetic-data-generation.pdf
- Personal Data Protection Commission, Singapore. “Proposed Guide on Synthetic Data Generation.” 2024. A*STAR case study on synthetic previews for regulated data collaboration. https://www.pdpc.gov.sg/-/media/files/pdpc/pdf-files/other-guides/proposed-guide-on-synthetic-data-generation.pdf
Generate Synthetic Data with the DataFramer MCP Server
Generate diverse synthetic data directly from your AI coding assistant using the DataFramer MCP server.
 Alex Lyzhov
Alex Lyzhov Golden Datasets, Eval Data, and Fine-Tuning Sets: Built by DataFramer
Raw LLMs can't generate multi-file records, edge cases, or labeled data at the fidelity AI teams need.
Puneet Anand Get started
Ready to build better AI with better data?
The real bottleneck in AI isn't intelligence. It's the data you can't generate, can't share, or can't trust.