Long-Form Synthetic Data Generation: Same LLM, Dramatically Different Results
Same LLM, dramatically different results. DataFramer vs raw Claude on 50K-token document generation.

Alex Lyzhov
Mon Jan 12
Summary
We generated 50K-token documents using the same frontier LLM and got dramatically different results. In the baseline, outputs collapsed into short, repetitive “summary essays”. With DataFramer’s scaffold, we consistently got full-length, style-faithful documents across 4 long-text datasets.
What surprised us most (real examples):
- Real Estate: baseline repeated “Zoning” 8 times; DataFramer produced 15 distinct topics from 5 inputs.
- Gutenberg: baseline reused the same plot loop; DataFramer generated genuinely varied stories with strong prose.
- Wiki Medical: baseline got shorter and added unwanted Markdown; DataFramer stayed long and encyclopedic.
Read on for:
- The exact evaluation setup (blind, Gemini 3 Pro)
- The three failure modes (mode collapse, style drift, length shrinkage) and how scaffolding prevents them
- Full outputs + scripts for reproducing our results
Introduction
Long-form synthetic text generation (10K-100K tokens per sample) is critical for LLM evaluation and for producing synthetic training data and fine-tuning datasets at scale. Modern LLMs routinely operate with very large prompts, extended chat histories, and agent trajectories. This is a challenging domain where maintaining coherence, diversity, and stylistic fidelity matters enormously.
Raw LLMs struggle here: autoregressive generation commits to tokens without lookahead, can’t revise earlier sections, and tends to drift or repeat as context grows. Long texts require global coherence that single-pass generation can’t guarantee. You need intermediate representations (outlines, state tracking), iterative search and editing, verification loops, and revision procedures. Long-form generation requires exactly that kind of scaffold.
What is DataFramer?
DataFramer is a synthetic data platform and synthetic dataset generator for producing high-quality synthetic datasets at scale, used to build evaluation datasets, golden datasets, and fine-tuning datasets, and for data augmentation workflows. You provide example data, and it generates new samples matching the same patterns, distributions, and structure. Under the hood, DataFramer’s agentic framework analyzes your seed datasets to create a specification capturing data properties and distributions, then runs generation with outlining, iterative evaluation loops and revision cycles. This is exactly the kind of intermediate representation and quality control that raw prompting lacks. For more details, see our documentation.
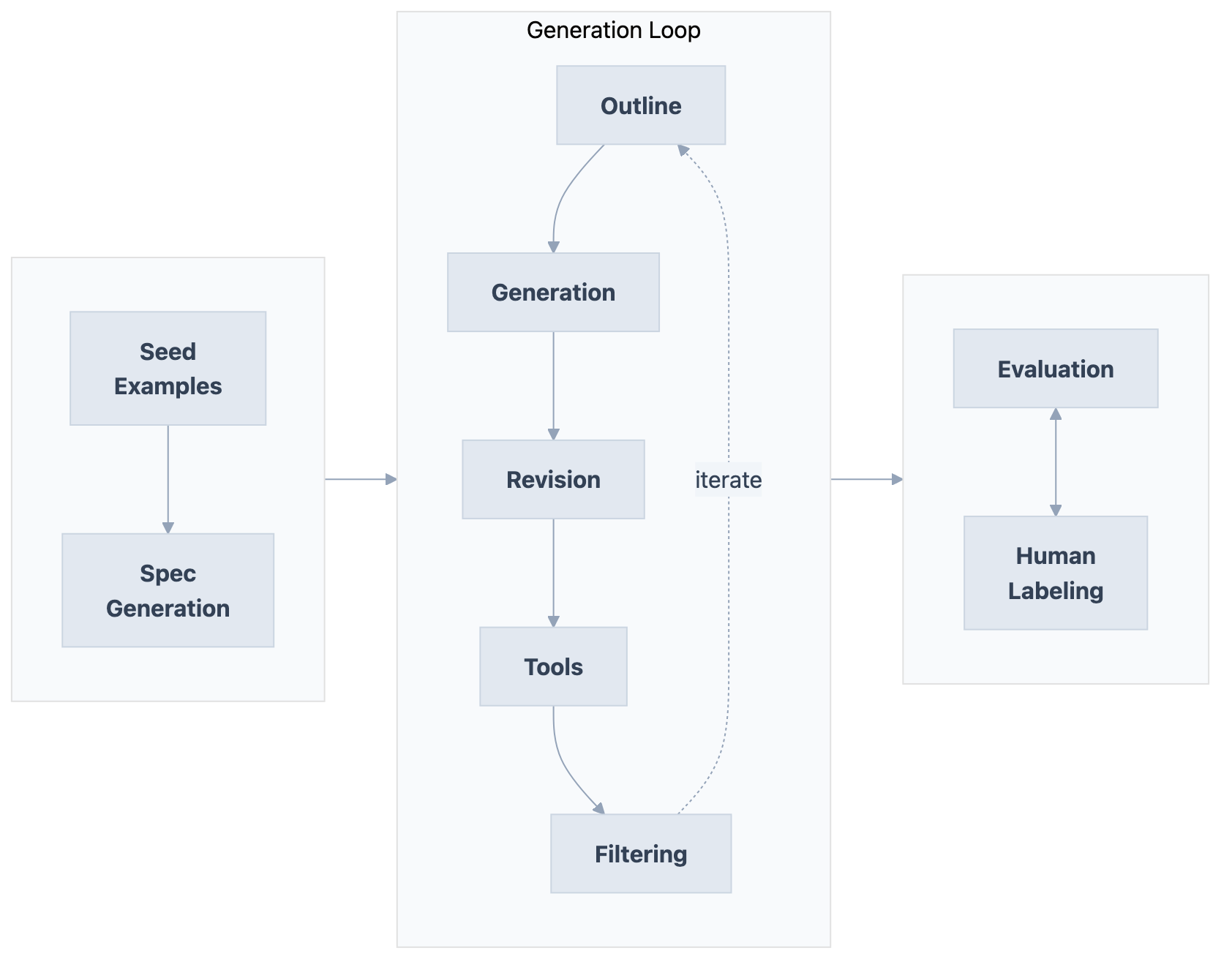
Experiment Setup
Datasets
We manually collected 4 datasets with long texts as seeds for style and formatting conditioning:
| Dataset | Source | Number of Samples | Sample Length | Description |
|---|---|---|---|---|
| Wikisource | Download | 2 texts | 35k-50k tokens | ”Results and Prospects” (Trotsky) + “The Time Machine” (H.G. Wells) |
| Gutenberg | Download | 2 texts | 45k-50k tokens | ”The Call of the Wild” (Jack London) + “The Time Machine” (H.G. Wells) |
| Wiki Medical | Download | 2 articles | 25k-30k tokens | ”Healthcare in Canada” + “History of Medicine” |
| Wiki Real Estate | Download | 5 articles | 5k-15k tokens | NIMBY, Real Estate Economics, Intellectual Property, Property Management, REITs |
Generation Protocol
We generated up to 15 samples for each dataset. Generation followed the standard flow and was almost completely hands-off:
- Load seed data
- Generate a spec using Claude Sonnet 4.5, a blueprint that captures the structure, patterns, and requirements of your data
- Make minimal spec edits (see below)
- Generate samples
The spec edits were trivial: we only made changes in 2 places across all 4 datasets. See the before/after specs:
| Dataset | Generated Spec | Edited Spec | Change |
|---|---|---|---|
| Wiki Medical | spec | (same) | No changes |
| Wikisource | before | after | Removed last sentence about length (platform determines length automatically) |
| Wiki Real Estate | spec | (same) | No changes |
| Gutenberg | before | after | Changed “from” to “resembling those from” (we want new fiction, not reproductions) |
There was no cherrypicking: we did not select datasets where DataFramer performs well, nor make algorithm changes for these datasets. All seed datasets, generation specs, and scripts are included for reproducibility.
Baseline
As of January 2026, to the best of our knowledge, we have not identified a commercially available system that provides comparable general-purpose generation of diverse long-form texts. Therefore, we compare against a raw frontier LLM baseline: Claude Sonnet 4.5 with low reasoning mode (1024 tokens of reasoning). DataFramer uses the same model for all its internal roles (outlining, generation, filtering, revision). The only difference between the two methods is our agentic framework.
Evaluation Methodology
We designed the LLM evaluation framework and eval harness to be maximally fair:
- Systems anonymized as “System 1” (DataFramer) and “System 2” (baseline Claude Sonnet 4.5), same number of samples for each
- We used an LLM as a judge approach with an independent evaluator from a different model family: Gemini 3 Pro Preview with high reasoning mode
- Evaluator received all samples from both systems in one context window and compared them across 7 dimensions: Diversity, Style Distribution Matching, Length, Quality, Artifacts, Validity, and Overall Assessment
Results
At a Glance
| Dataset | DataFramer | Baseline (Sonnet 4.5) |
|---|---|---|
| Wikisource | Full novellas with compelling plots, authentic period voices | Only produced dry essays, ignored fiction entirely |
| Gutenberg | Superb prose quality, massive creativity | Plot loop - same expedition story repeated |
| Wiki Real Estate | 15 unique topics from 5 inputs, perfect style match | 8x “Zoning”, 4x “Land Value Tax” |
| Wiki Medical | Long-context coherence, encyclopedic depth | Too short, added unwanted Markdown formatting |
The same model, the same seeds. The only difference is DataFramer’s agentic scaffold.
Deep Dive: Wikisource
| Criterion | DataFramer | Sonnet 4.5 Baseline |
|---|---|---|
| Diversity | Exceptional - political treatises, epistolary novels, sci-fi, utopias. Creatively merges both inputs. | Very low - nearly all dry expository essays. No fiction, no dialogue. Repetitive titles. |
| Style Distribution | Matches both input styles. Reproduces Wikisource formatting (nav arrows, metadata). Authentic period voices. | Fails - homogenizes everything into generic “academic” voice. |
| Length | Massive long-form content - full novellas with Preface to Epilogue structure. | Short-medium essays, summary-based, lacking depth. |
| Quality | Extraordinary - compelling plots, character arcs, authentic world-building. | Mediocre - reads like undergraduate summaries. |
| Artifacts | Intentionally reproduces Wikisource artifacts (nav links, page numbers). | Strips all formatting. |
| Validity | High - historically grounded, internally consistent. | Moderate - logically sound but platitudinous. |
Winner: DataFramer (vastly superior)
The other three datasets showed consistent patterns: DataFramer maintained diversity and style fidelity while the baseline collapsed into repetitive outputs (Gutenberg: same plot structure repeated; Wiki Real Estate: 80% duplicate topics) and introduced unwanted formatting changes.
Full Evaluation Details
Evaluation summaries and full reports:
- Wikisource: Summary | Full
- Gutenberg: Summary | Full
- Wiki Real Estate: Summary | Full
- Wiki Medical: Summary | Full
All generated outputs (both DataFramer and baseline) are available for download:
- Wikisource: Download outputs
- Gutenberg: Download outputs
- Wiki Real Estate: Download outputs
- Wiki Medical: Download outputs
All data (seeds, DataFramer outputs, and baseline outputs) is also available on HuggingFace.
DataFramer Avoids Typical Synthetic Data Failure Modes
The blind evaluation revealed three distinct failure modes in the baseline that DataFramer successfully avoids:
Failure Mode 1: Mode Collapse
The baseline repeatedly generates the same topics or formulaic plot structures. In Wiki Real Estate, “Zoning” appeared 8 times and “Land Value Tax” 4 times out of 15 samples. In Gutenberg, every story followed the same arc: ship, island, ruins, beings, escape. In Wiki Medical, duplicate “Medical Education” articles appeared.
DataFramer avoids this through diversity injections during the outlining phase, ensuring each sample covers different ground within the topic space defined by the seeds.
Failure Mode 2: Style Drift
The baseline introduces formatting and structural elements not present in the seed data: adding Markdown headers when inputs used plain text, converting dense encyclopedic prose into bullet-point lists, and stripping source-specific formatting artifacts like Wikisource navigation and metadata.
DataFramer avoids this through iterative evaluation and editing loops that keep the generated style tightly matched to the original distribution, continuously comparing output characteristics against seed characteristics.
Failure Mode 3: Length Shrinkage
The baseline generates summaries instead of full documents. Wikisource seeds were 35k-50k tokens; baseline outputs were 2k-5k tokens. Dense, chapter-length inputs became brief essays.
DataFramer addresses this by explicitly accounting for target length during outlining and generation, maintaining long-context coherence through structured revision passes.
Discussion
There are many aspects of synthetic data quality that need to be monitored: coherence, diversity, specification matching, length profiles, and more. Missing any one of these can result in an unusable dataset.
Our evaluation shows that naive prompting of frontier models collapses into repetitive, homogenized outputs. DataFramer’s agentic scaffold (outlining, generation, filtering, and revision stages) produces dramatically better results using the exact same underlying model.
For practitioners building synthetic data generation pipelines:
- Watch for mode collapse: Count unique topics/structures in your outputs
- Watch for style drift: Compare formatting and structure to your inputs
- Watch for length shrinkage: Are your outputs significantly shorter than your inputs?
One approach satisfies your specifications. The other collapses into repetitive, homogenized outputs. Beyond these three failure modes, raw LLM generation also introduces LLM hallucination: fabricated values and invented facts that accumulate silently across large runs. DataFramer’s verification and revision loops are designed to catch these before they reach your dataset.
For a full breakdown of where DataFramer differs from raw LLM generation, see Why DataFramer.
Synthetic Text-to-SQL Data Generation with 100% SQL Validity Using Claude Haiku
How we generated 500 diverse, 100% valid text-to-SQL samples for LLM evaluation and fine-tuning using only Claude Haiku.
Alex Lyzhov Benchmarking Coding Agents as Math Auditors: A Synthetic Financial Document Dataset
We built a financial benchmark with planted errors to test Claude Code as a math auditor — no manual labeling needed.
Alex Lyzhov Building a Cyber Insurance Evaluation Dataset in 3 Easy Steps with DataFramer.
Scale a few real cyber insurance samples into a full evaluation and training dataset in three steps.
 Puneet Anand
Puneet Anand Get started
Ready to build better AI with better data?
DataFramer is an agentic framework for generating large structured or unstructured synthetic datasets at scale. Interested in generating high-quality data for your use case? Just reach out to us.