The Essential Guide to Synthetic Data
This guide explains what synthetic data is, how it's generated, and why it matters across industries like finance, healthcare, insurance, and technology. It covers benefits, case studies, generation techniques, vendor comparisons, anonymization, and real-world case studies showing synthetic data in action.

Puneet Anand
Fri Aug 22

Table of Contents
What is Synthetic Data, and is it Really “Synthetic”?
Types of Synthetic Data Used in the Industry
How Synthetic Data is Generated
Anonymization and Synthetic Data
Benefits of Using Synthetic Data
Top Use Cases Across Industries
Case Studies
Most Popular Tools
Conclusion
”We’ve now exhausted the cumulative sum of human knowledge in AI training … the only way to then supplement [real-world data] is with synthetic data”
- Elon Musk
What is Synthetic Data, and is it Really “Synthetic”?
Synthetic data has grown in popularity within the AI, Healthcare, and Finance communities over the past five years. Yet, a frequent reaction when the concept is introduced is:
It is synthetic. Is it fake? We are humans and we don’t like fake.
Synthetic data refers to information that is generated artificially rather than collected directly from real-world events or individuals. It is created using statistical models, simulation engines, or generative techniques designed to reproduce the patterns, distributions, and relationships found in authentic datasets.
For example, instead of using 10,000 actual medical records with sensitive patient identifiers, the structure of those records can be learned and used to create 100,000 new records that behave statistically the same way, but contain no identifiable patient data! These synthetic records allow healthcare researchers to conduct experiments and train models without ever handling protected health information.
 Graphic explaining the difference between Real Data, Anonymized, and Synthetic Data
Graphic explaining the difference between Real Data, Anonymized, and Synthetic Data
By design, synthetic data seeks to strike a balance: it is close enough to the real world to be useful for testing, analysis, benchmarking, and training ML models, but different enough to avoid the risks of privacy violations or restricted access.
Types of Synthetic Data Used in the Industry
Different industries adopt synthetic data in varied forms. While the underlying principle is the same, the techniques differ depending on the context and use case.
Tabular and Structured Synthetic Data
This is the most common type, where datasets with rows and columns (like financial transactions, claims data, or survey responses) are reproduced synthetically. For instance, a bank can generate millions of synthetic credit card transactions to test fraud detection systems without exposing any customer information!
Text-Based Synthetic Data
This type involves creating synthetic corpora of documents, chat logs, or electronic records. In regulated industries such as healthcare, startups have used synthetic electronic medical records (EMRs) to demonstrate product capabilities during proof-of-concept pilots without waiting for compliance teams to release real PHI.
Image and Video Synthetic Data
Used heavily in autonomous driving, robotics, and computer vision applications. Simulated environments can generate thousands of variations of rare or hazardous scenarios—such as a pedestrian crossing at dusk in heavy rain—that would be costly or unsafe to collect in reality.
Time-Series and Sensor Synthetic Data
These include logs from servers, IoT sensors, or predictive maintenance systems. Manufacturers can model synthetic sensor outputs to train fault detection algorithms before real breakdown data exists.
Hybrid Human + Synthetic Data
Some workflows blend small sets of carefully collected human data with large-scale synthetic augmentation. For example, in natural language processing, a few thousand high-quality annotated texts may be expanded with millions of synthetic samples to build robust models.
How Synthetic Data is Generated
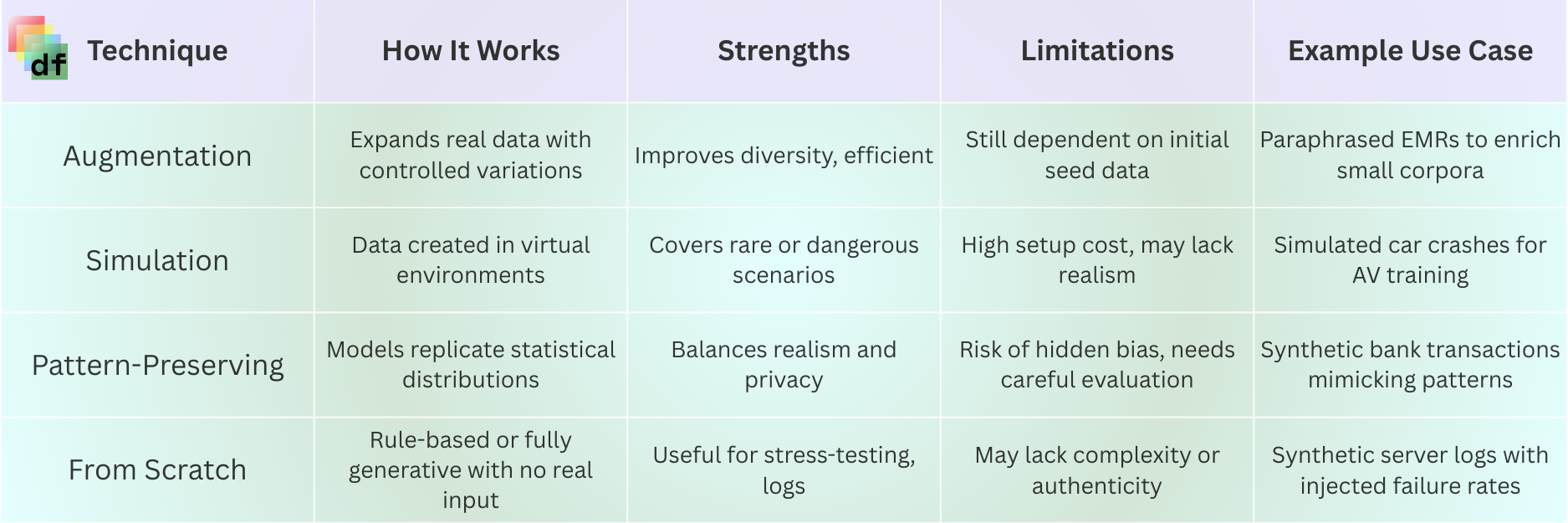 Comparison of various Synthetic Data Generation Techniques
Comparison of various Synthetic Data Generation Techniques
While synthetic data may look like it is real, the ways it is created can be different. Understanding these methods is essential for evaluating how trustworthy and useful a dataset will be for the task at hand.
And if you were wondering - yes, different data generation techniques can be great for different use cases, and you can apply multiple approaches in the same generation.
Augmented Synthetic Data
Augmentation expands an existing dataset by introducing controlled variations. In healthcare, a small sample of discharge summaries can be expanded by paraphrasing sentences, inserting plausible variations, or introducing noise. This allows AI systems to see more diverse examples while still grounded in the structure of the original data.
Simulated Synthetic Data
Simulation relies on engines or virtual environments to produce data. Insurers might simulate years of claims data to stress-test pricing models. In technology, autonomous driving firms create thousands of edge-case scenarios in simulation that would be prohibitively expensive or even dangerous to stage in reality.
Pattern-Preserving Synthetic Data
Pattern-preserving generation involves training a model on real datasets to capture their statistical relationships. For example, synthetic bank transaction data can maintain the correlation between income, geography, and spending behavior without reproducing any real customer’s information. This is a common approach for tabular and text-based synthetic data.
Created Entirely From Scratch
Some synthetic datasets are generated from first principles using rules and constraints rather than any seed data. A company might define error-rate probabilities and log formats to create synthetic server logs. Although such data may lack the full nuance of real-world distributions, it is effective for starting projects or testing systems under controlled conditions.
Anonymization and Synthetic Data
Anonymization is Different from Synthetic Data Generation
Anonymization edits or masks real records, for instance, by removing names, replacing IDs, and blurring faces. But the data itself is still real, which means re-identification is sometimes possible if it’s cross-referenced with other sources. Synthetic data, by contrast, creates entirely new records that only copy the patterns of the original. There’s no hidden “real person” under the hood.
Synthetic Data as a way to achieve Anonymization
Synthetic generation can serve as a form of anonymization. Instead of sharing edited records, an organization trains a model on sensitive data and produces a synthetic copy. Hospitals, for example, use synthetic EMRs to let researchers work with patient-like data without exposing anyone’s health information. Banks do the same with synthetic transaction logs when testing fraud systems with vendors. However, please note that Synthetic Data generation doesn’t guarantee anonymization unless it is explicitly created with it in mind.
Benefits of Using Synthetic Data
The appeal of synthetic data lies in the combination of privacy, scalability, and cost efficiency. Enterprises and researchers have highlighted several key benefits.
Privacy and Compliance
Synthetic data allows organizations to work with sensitive domains—health records, financial transactions, insurance claims—without breaching privacy regulations. By ensuring no real individual can be re-identified, organizations can bypass delays from legal reviews and compliance bottlenecks.
Scalability and Coverage
It is often expensive and sometimes impossible to collect enough real-world examples, especially for rare events. Synthetic generation makes it possible to create balanced datasets that cover edge cases, ensuring models are not trained only on the majority class.
Cost Reduction
Data collection and labeling represent the majority of cost in many AI projects. Synthetic augmentation significantly reduces reliance on manual labeling, cutting both time and expense.
Experimentation and Innovation
Synthetic data enables faster proof-of-concept cycles. Startups, in particular, can demonstrate to potential enterprise customers how their product works using synthetic replicas rather than waiting months for access to real, sensitive data.
Bias Mitigation
Real-world data often reflects historical biases. Synthetic data can be engineered to increase representation of underrepresented groups, reducing downstream bias in models.
Top Use Cases Across Industries
Finance
Banks and fintechs rely on data to detect fraud, evaluate credit risk, and ensure compliance with anti-money laundering (AML) and know-your-customer (KYC) regulations. The challenge is that fraudulent transactions are extremely rare, making datasets highly imbalanced. Synthetic financial datasets are used to generate realistic fraudulent events so that models learn to spot them.
Example: A global financial institution created millions of synthetic wire transfers designed to mimic fraud signals. This boosted recall in fraud detection models without exposing any real customer information.
Healthcare
In healthcare, patient privacy is paramount. Synthetic patient data, including EMRs and clinical trial records, allows for training diagnostic AI systems without risking HIPAA violations. Pharmaceutical companies are also exploring synthetic cohorts to simulate trial arms, reducing cost and accelerating drug development.
Example: A health-tech startup generated synthetic oncology patient records with added “messiness” such as fax-like formatting and scanned handwriting. This allowed them to test AI models under realistic conditions while avoiding the need for access to live hospital data.
Insurance
Insurers rely on claims data to optimize underwriting, assess fraud risk, and streamline claims processing. Synthetic insurance claims data enables simulation of fraudulent patterns and rare catastrophic scenarios, such as multiple overlapping claims during a natural disaster.
Example: An insurer used synthetic claims data to stress-test their automated claims adjudication system for unusual edge cases that had never occurred historically but could create vulnerabilities.
Technology
For general tech and AI companies, synthetic data provides a critical way to scale models. In natural language processing, synthetic text corpora allow teams to augment smaller real datasets. In system engineering, synthetic log data is used to test how software behaves under unusual stress conditions.
Example: A cloud provider used synthetic server log data to simulate outages and measure the resilience of monitoring systems.
Case Studies
Real-world adoption shows how synthetic data is not just a theoretical tool but a practical solution to some of the toughest challenges in regulated industries. Here are four examples.
A. Training AI Models for Fraud Detection in Finance
Problem: Fraudulent transactions are rare compared to normal ones. This imbalance makes it hard for financial institutions to train accurate fraud detection models.
Solution: J.P. Morgan used synthetic data to rebalance training sets, generating realistic fraudulent transactions alongside normal ones. By exposing AI systems to more examples of suspicious activity, models could better learn the subtle signs of fraud.
Benefit: The models trained on synthetic datasets performed better at spotting anomalies. By design, the synthetic data contained a higher proportion of fraudulent behavior, helping systems catch what would otherwise go unnoticed.
B. Testing AI Models for Bias in Multi-Label Settings
Problem: Mastercard applies multi-label AI models in areas like fraud prevention, anti-money laundering, and marketing optimization. These models risk learning unintended demographic biases, but studying bias is difficult because demographic data is sensitive and not easily shared.
Solution: Mastercard worked with researchers to generate synthetic datasets that safely represented demographic patterns without exposing private attributes. These synthetic datasets supported the development of new methods to detect and correct bias in multi-label models.
Benefit: Synthetic data provided a safe bridge: private enough to share externally, but realistic enough to reflect the underlying relationships in the real data. This enabled insights into fairness that would have been impossible using only confidential datasets.
C. Protecting Patient Privacy in Healthcare Research
Problem: Johnson & Johnson allowed external researchers access to anonymized healthcare datasets. But traditional anonymization often degraded data quality, leaving researchers frustrated with incomplete or less useful datasets.
Solution: J&J introduced AI-generated synthetic healthcare records as an alternative to classic anonymization. These records preserved population-level patterns while removing direct identifiers.
Benefit: Researchers found the synthetic datasets far more useful, offering a realistic view of patient populations while still protecting privacy. This improved the depth and accuracy of healthcare analysis.
D. Enabling Data Collaboration in a Regulated Environment
Problem: A pharmaceutical company needed access to heart health data from a research institute. The data existed but was locked in a highly regulated environment, blocking flexible collaboration.
Solution: A*STAR, a Singapore-based research agency, built a pipeline to create synthetic versions of the heart health data. These synthetic datasets could be shared outside the regulated environment while keeping the original secure.
Benefit: The pharmaceutical company previewed the synthetic data to validate quality and usefulness before committing to a high-value purchase of the actual dataset. This reduced risk, built confidence, and sped up the collaboration process.
Source: Personal Data Protection Commission, Singapore
Most Popular Tools
A growing ecosystem of vendors and platforms has emerged to meet demand for synthetic data. A few widely recognized names include:
Gretel.ai - Known for its strong APIs and focus on structured and text-based synthetic data. Popular among enterprises needing data anonymization and compliance.
MOSTLY AI - Widely adopted for its high-fidelity tabular synthetic data and focus on enterprise-grade compliance and governance.
Hazy - Specializes in time-series and financial datasets, with strong emphasis on differential privacy and regulatory adherence.
Synthea - An open-source tool primarily used to generate synthetic healthcare data, particularly patient records, often used in research and teaching contexts.
Synthesis AI - Focused more on image and vision-based synthetic data, supporting AR/VR and computer vision use cases.
Dataframer - A newer entrant focused specifically on structured and unstructured text use cases. Dataframer differentiates itself through a transparent workflow of seed input, variation analysis, and controlled generation, allowing enterprises to build governance and fairness directly into text data pipelines.
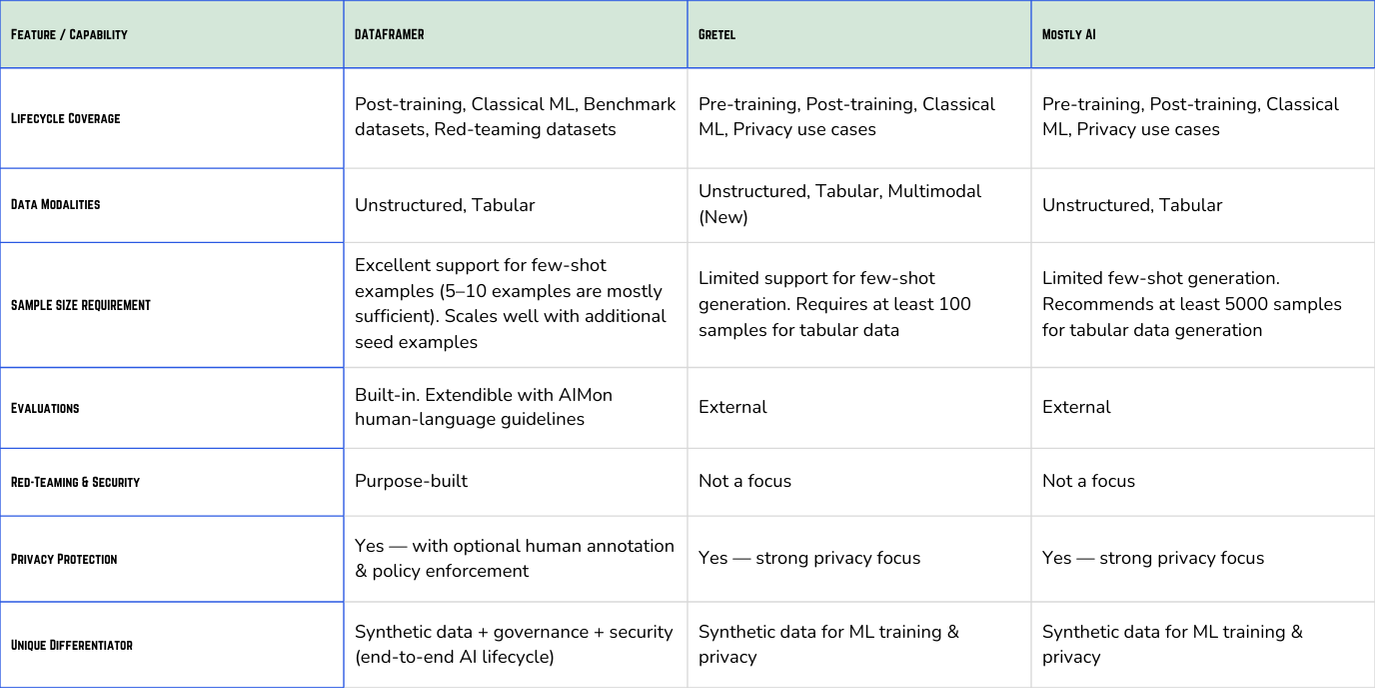
Comparison of Dataframer and most popular synthetic data generation platforms
Conclusion
Synthetic data has become a cornerstone of enterprise AI strategies across finance, healthcare, insurance, and technology. By addressing the long-standing challenges of privacy, data scarcity, bias, and cost, synthetic data enables faster innovation while protecting individuals and organizations from compliance risks.
As adoption accelerates, the winners in the ecosystem will be those who balance fidelity, governance, and ease of integration. For practitioners, the opportunity is clear: treat synthetic data not as a replacement for real data, but as a multiplier!
Get started
Ready to build better AI with better data?
The real bottleneck in AI isn't intelligence. It's the data you can't generate, can't share, or can't trust.