Precision Synthetic Data for your AI, under your control.
Roll AI out 70% faster at a fraction of the cost by instantly simulating, augmenting, generating and anonymizing datasets.







Build Trustworthy AI
Privacy-preserving datasets (HIPAA, GDPR, SOC2) that comply with the strictest regulations.
Fill demographic and behavioral gaps to ensure fairer, bias-free models.
Synthetic "safe data" for faster POCs — prove value without waiting for real customer data.
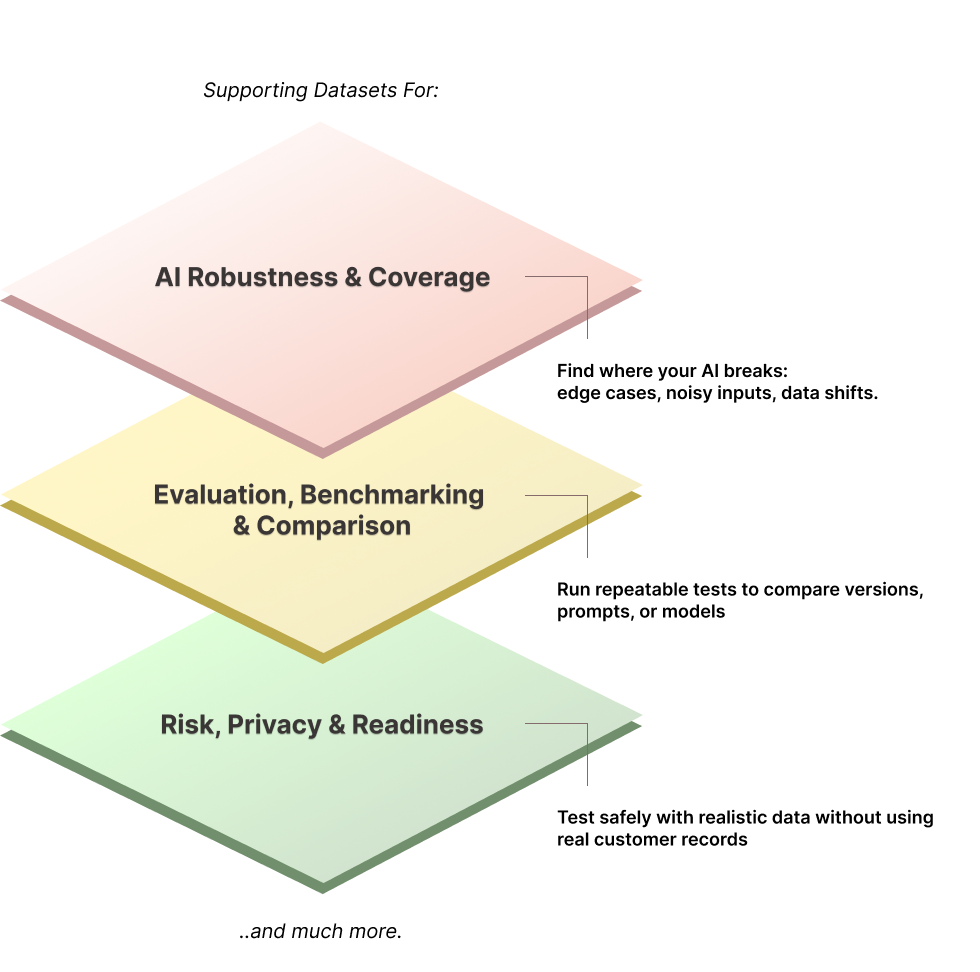
Test and train your models for the real world, including the rare edge cases
-
Fill gaps and simulate rare or dangerous scenarios at scale.
Simulate fraud attempts, rare medical conditions, or complex financial scenarios at scale.
Augment human-labeled data with synthetic generation: humans focus on nuance, AI handles volume.
Build resilient models that don’t break in the wild.
Privacy-Safe AI Evaluations and Development
Dataframer generates fully synthetic datasets that preserve statistical fidelity while removing or masking PII/PHI. Enterprises can test and train models without exposing customer data.
- Compliance with HIPAA, GDPR, SOC2
- Build AI without risking leaks
- Unlock access to restricted datasets for faster iteration
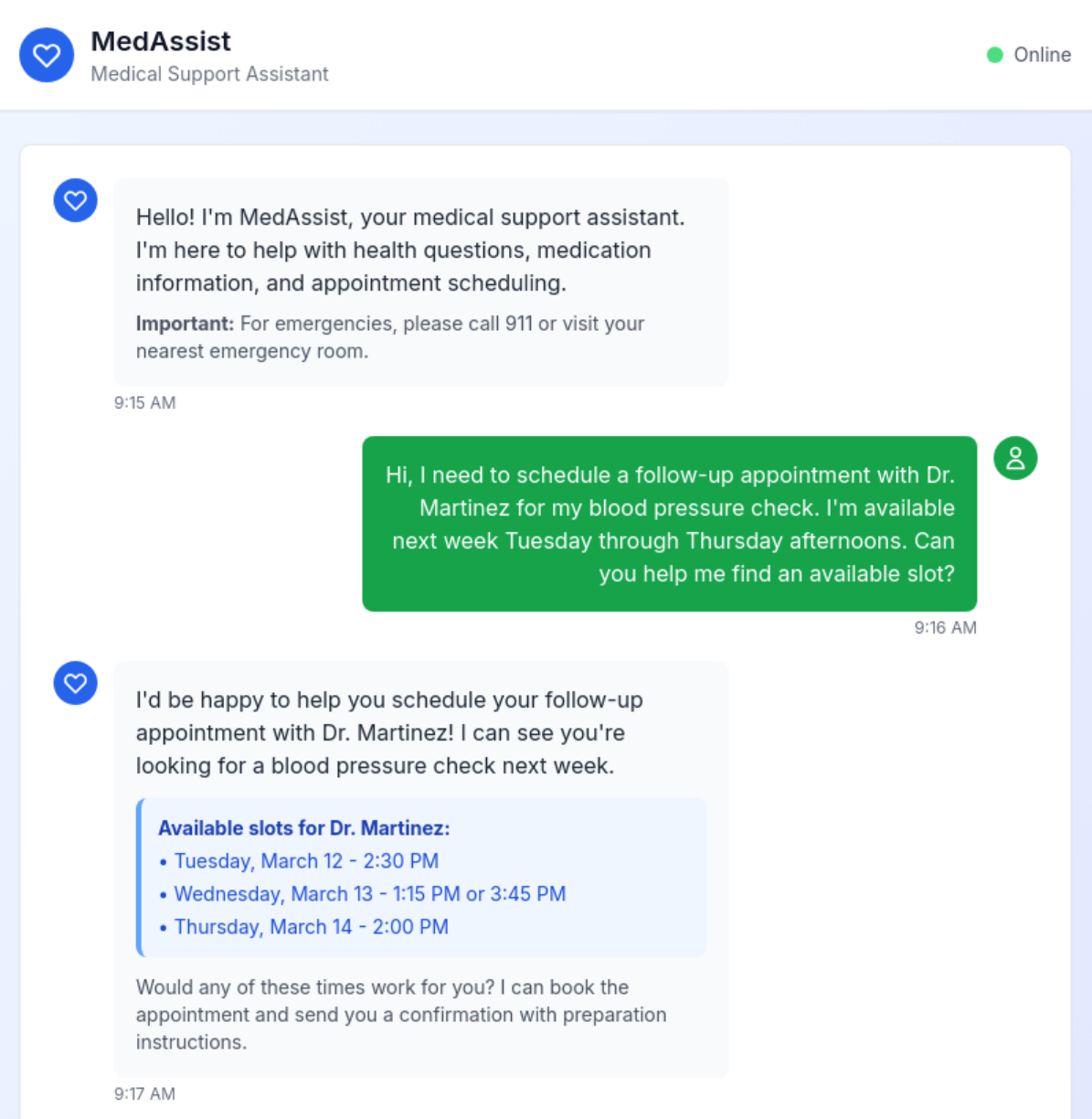
Smarter, Safer Conversational AI
Dataframer simulates multi-turn dialogues, including rare or adversarial scenarios, to stress-test chatbot logic before deployment.
- Train bots on rare/edge cases
- Improve handling of context over long conversations
- Reduce failure modes and hallucinations
Bias-Free, Realistic Tabular Data
Dataframer expands tabular datasets with realistic synthetic records that mirror true numerical distributions (e.g., transactions, claims). Gaps and imbalances are corrected automatically.
- Fairer AI decisions across demographics
- Safe financial data that's accurate to distributions
- Fill gaps in edge cases for risk/fraud modeling
Boost Model Accuracy with Synthetic ML Data
Dataframer generates rare events and minority-class examples, strengthening training datasets for anomaly detection, classification, risk scoring, and recommendation engines.
- Improve recall on rare anomalies
- Reduce false negatives in risk models
- Better personalization for recommendations
Stronger Models for Text & Document AI
Dataframer creates synthetic long-form documents with labeled entities, section structures, and complex layouts. Perfect for training extraction models without licensing or compliance hurdles.
- Train on larger, richer document sets
- Handle edge cases (nested entities, long spans)
- Reduce annotation costs for long text corpora
Generate pre-evaluated datasets
with an easy-to-use UI or API
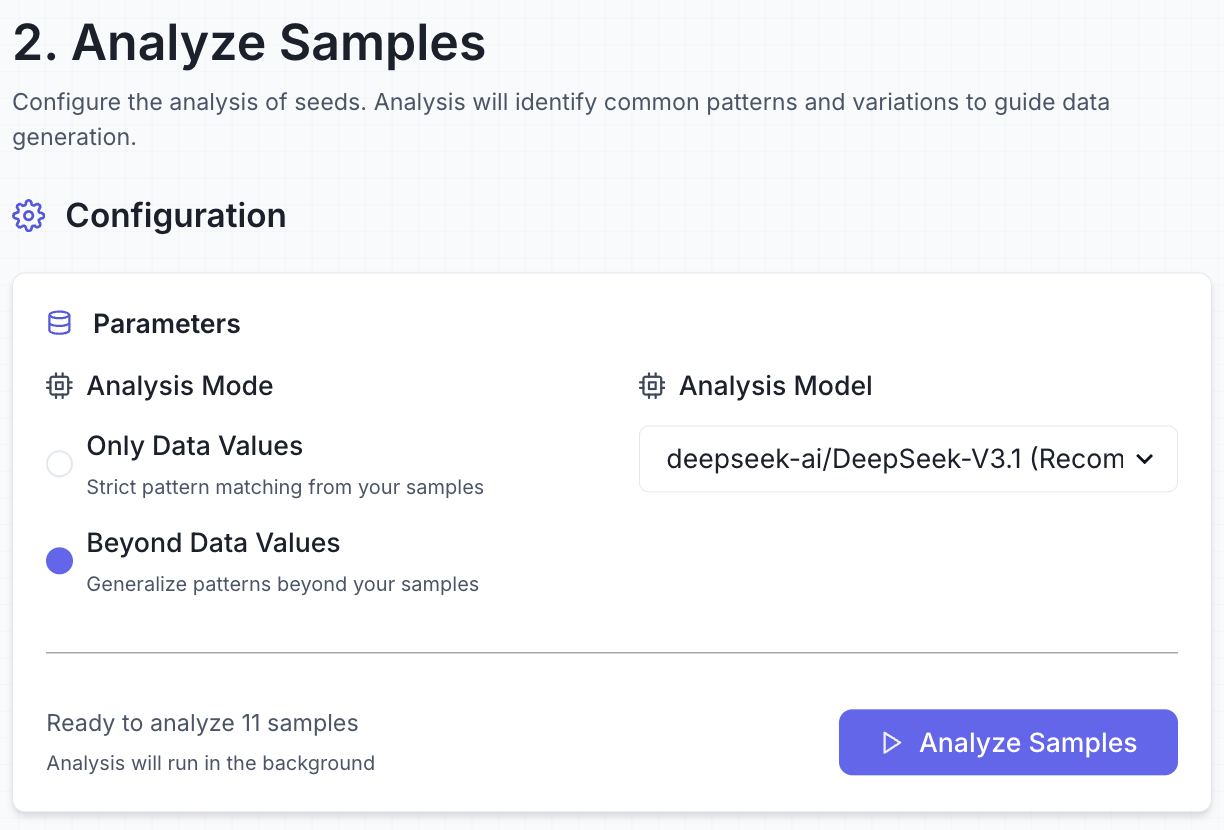
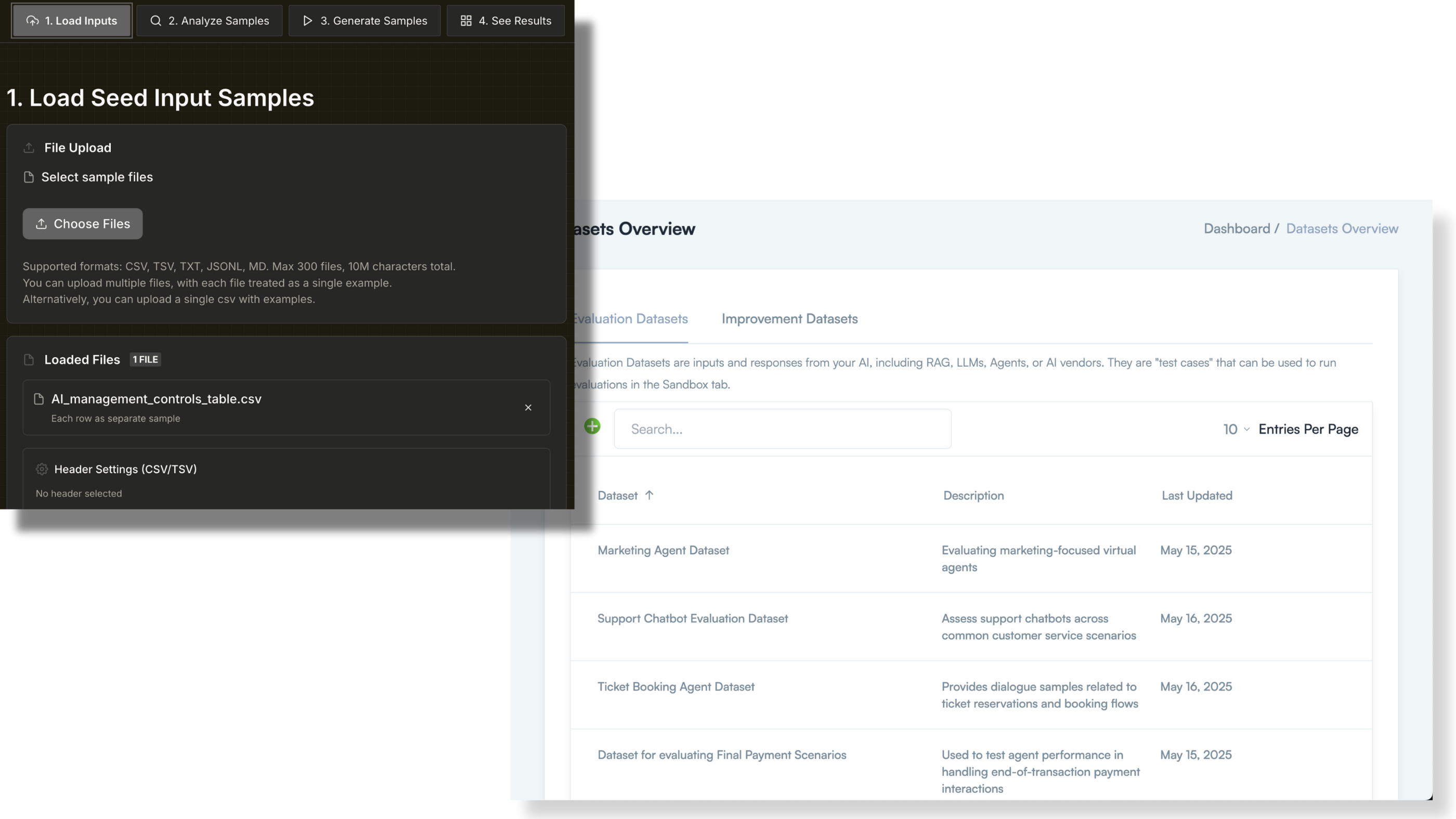
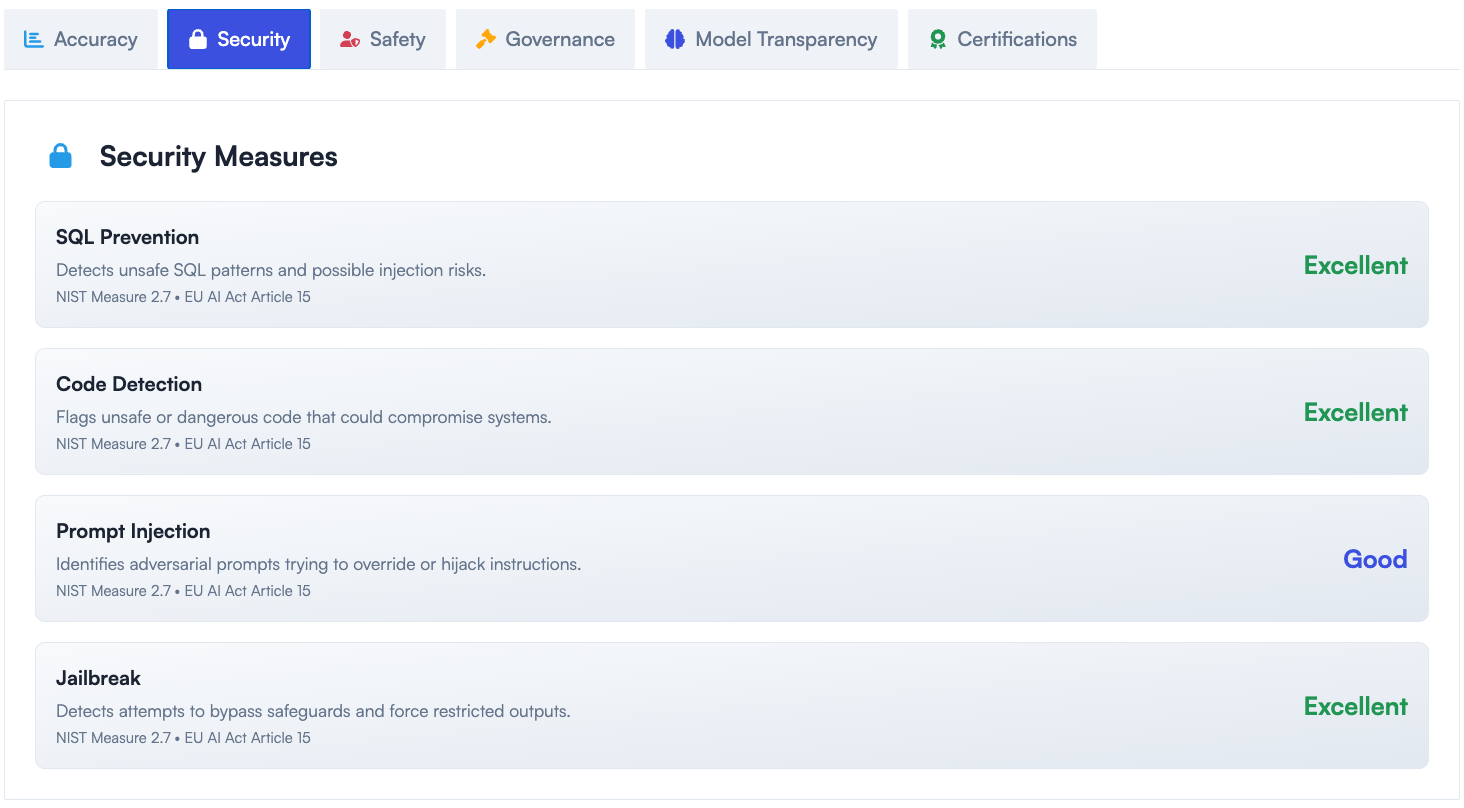
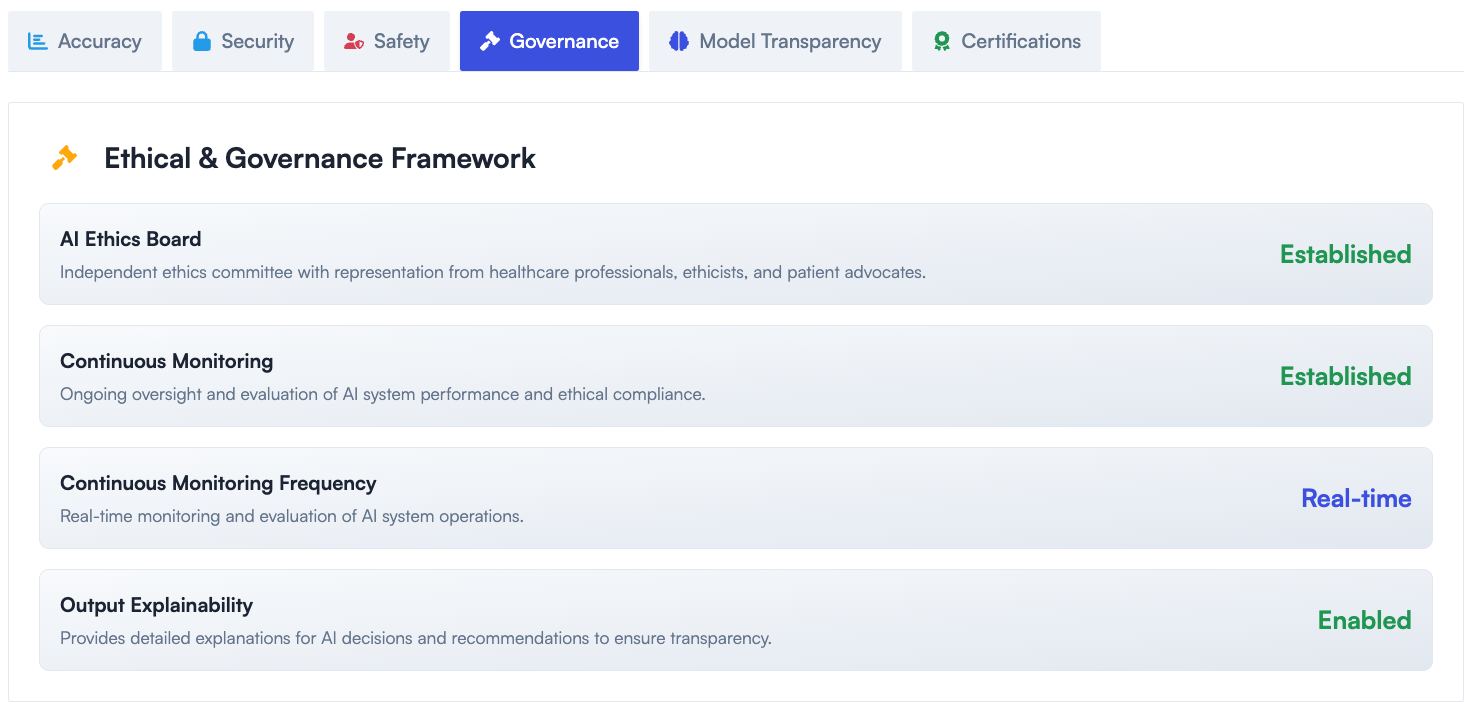
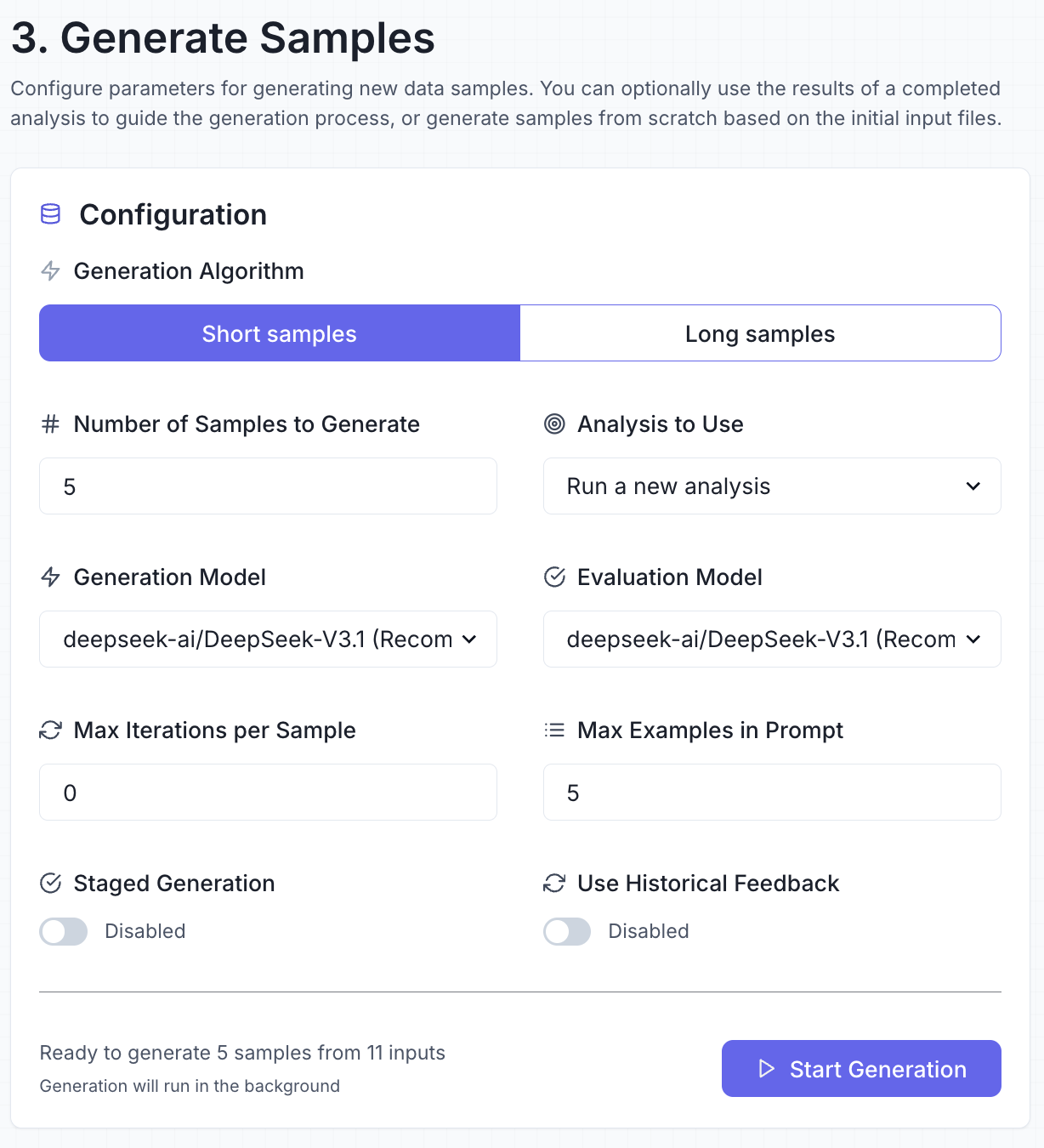
Why DataFramer?
Structured Workflow with API Access
Dataframer combines a clear three-step workflow (Seed, Analysis, Generation) with full API integration. This balance of transparency and automation ensures scalable synthetic data generation with strong governance.
Control over Data Properties (Axes of Variation)
The platform automatically identifies attributes and variables in the seed data before generation. This gives teams precise control over dataset diversity and ensures better coverage of underrepresented scenarios.
Evaluation Built In
Continuous evaluation is embedded in the platform, including quality, validity, diversity, PII, and fairness checks. Enterprises can validate and label generated datasets without relying on separate external tools.
Text-First by Design
Purpose-built for structured and unstructured text, including formats like CSV, Parquet, SQL extracts, JSON, and JSONL document corpora. Optimized for enterprise NLP and LLM evaluation and fine-tuning.
Designed for Developers and Enterprises
Easy defaults and fast setup make Dataframer accessible for small teams, while scalability, compliance features, and reporting address enterprise-level requirements.
Fairness and Bias Mitigation
Built-in controls allow balancing of underrepresented groups and validation of fairness during generation. This ensures synthetic datasets are inclusive, representative, and trustworthy.
FAQ
Frequent questions and answers
What is Dataframer?
How does Dataframer work?
How do I trust Dataframer?
What formats can I upload?
Do I need my own data to get started?
How is Dataframer different from anonymization or masking?
Can I use Dataframer for compliance-heavy industries like healthcare or finance?
What are common use cases that Dataframer can help me with?
How does Dataframer handle long-form text?
Can I control the output?
How does Dataframer ensure quality?
What's the ROI of using Dataframer?
How can I deploy Dataframer?
Get Started
Ready to accelerate AI POCs?
Book a consultation or get your free AI assessment today.